一、准备知识
在阅读本文之前,需要读者至少了解以下基础知识
- CPU Cache的基本概念,具体可参见 关于CPU Cache – 程序猿需要知道的那些事。
- NUMA的基本概念,具体可参见 NUMA架构的CPU — 你真的用好了么?。
- 目前Linux基于多核CPU繁忙程度的线程调度机制,参看
Chip Multi Processing aware Linux Kernel Scheduler论文。
本文将分析是否HugePage在任何条件下(特别是NUMA架构下)都能带来性能提升。
二、关于HugePage
在正式开始本文分析前,我们先大概介绍下HugePage的历史背景和使用场景。
为什么需要HugePage?了解CPU Cache大致架构的话,一定听过TLB Cache。Linux系统中,对程序可见的,可使用的内存地址是Virtual Address。每个程序的内存地址都是从0开始的。而实际的数据访问是要通过Physical Address进行的。因此,每次内存操作,CPU都需要从page table中把Virtual Address翻译成对应的Physical Address,那么对于大量内存密集型程序来说page table的查找就会成为程序的瓶颈。所以现代CPU中就出现了TLB(Translation Lookaside Buffer) Cache用于缓存少量热点内存地址的mapping关系。然而由于制造成本和工艺的限制,响应时间需要控制在CPU Cycle级别的Cache容量只能存储几十个对象。那么TLB Cache在应对大量热点数据Virual Address转换的时候就显得捉襟见肘了。我们来算下按照标准的Linux页大小(page size) 4K,一个能缓存64元素的TLB Cache只能涵盖4K*64 = 256K的热点数据的内存地址,显然离理想非常遥远的。于是HugePage就产生了。 Tips: 这里不要把Virutal Address和Windows上的虚拟内存搞混了。后者是为了应对物理内存不足,而将内容从内存换出到其他设备的技术(类似于Linux的SWAP机制)。

什么是HugePage既然改变不了TLB Cache的容量,那么只能从系统层面增加一个TLB Cache entry所能对应的物理内存大小,从而增加TLB Cache所能涵盖的热点内存数据量。假设我们把Linux Page Size增加到16M,那么同样一个容纳64个元素的TLB Cache就能顾及64*16M = 1G的内存热点数据,这样的大小相较上文的256K就显得非常适合实际应用了。像这种将Page Size加大的技术就是HugePage。
三、HugePage是万能的?
了解了HugePage的由来和原理后,我们不难总结出能从HugePage受益的程序必然是那些热点数据分散且至少超过64个4K Page Size的程序。此外,如果程序的主要运行时间并不是消耗在TLB Cache Miss后的Page Table Lookup上,那么TLB再怎么大,Page Size再怎么增加都是徒劳。在LWN的一篇入门介绍中就提到了这个原理,并且给出了比较详细的估算方法。简单的说就是:先通过oprofile抓取到TLB Miss导致的运行时间占程序总运行时间的多少,来计算出HugePage所能带来的预期性能提升。 简单的说,我们的程序如果热点数据只有256K,并且集中在连续的内存page上,那么一个64个entry的TLB Cache就足以应付了。说道这里,大家可能有个疑问了:既然我们比较难预测自己的程序访问逻辑是否能从开启HugePage中受益。反正HugePage看上去只改了一个Page Size,不会有什么性能损失。那么我们就索性对所有程序都是用HugePage好啦。 其实这样的想法是完全错误的!也正是本文想要介绍的一个主要内容,在目前常见的NUMA体系下HugePage也并非万能钥匙,使用不当甚至会使得程序或者数据库性能下降10%。下面我们重点分析。
四、HugePage on NUMA
Large Pages May Be Harmful on NUMA Systems一文的作者曾今做过一个实验,测试HugePage在NUMA环境的各种不同应用场景下带来的性能差异。从下图可以看到HugePage对于相当一部分的应用场景并不能很好的提升性能,甚至会带来高达10%的性能损耗。

性能下降的原因主要有以下两点
1. CPU对同一个Page抢占增多
对于写操作密集型的应用,HugePage会大大增加Cache写冲突的发生概率。由于CPU独立Cache部分的写一致性用的是MESI协议,写冲突就意味:
- 通过CPU间的总线进行通讯,造成总线繁忙
- 同时也降低了CPU执行效率。
- CPU本地Cache频繁失效
类比到数据库就相当于,原来一把用来保护10行数据的锁,现在用来锁1000行数据了。必然这把锁在线程之间的争抢概率要大大增加。
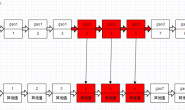
2. 连续数据需要跨CPU读取(False Sharing)
从下图我们可以看到,原本在4K小页上可以连续分配,并因为较高命中率而在同一个CPU上实现locality的数据。到了HugePage的情况下,就有一部分数据为了填充统一程序中上次内存分配留下的空间,而被迫分布在了两个页上。而在所在HugePage中占比较小的那部分数据,由于在计算CPU亲和力的时候权重小,自然就被附着到了其他CPU上。那么就会造成:本该以热点形式存在于CPU2 L1或者L2 Cache上的数据,不得不通过CPU inter-connect去remote CPU获取数据。 假设我们连续申明两个数组,Array A和Array B大小都是1536K。内存分配时由于第一个Page的2M没有用满,因此Array B就被拆成了两份,分割在了两个Page里。而由于内存的亲和配置,一个分配在Zone 0,而另一个在Zone 1。那么当某个线程需要访问Array B时就不得不通过代价较大的Inter-Connect去获取另外一部分数据。
四、对策
理想
我们先谈谈理想情况。上文提到的论文其实他的主要目的就是讨论一种适用于NUMA架构的HugePage自动内存管理策略。这个管理策略简单的说是基于Carrefour的一种对HugePage优化的变种。(注:不熟悉什么是Carrefour的读者可以参看博客之前的科普介绍或者阅读原文) 下面是一些相关技术手段的简要概括:
- 为了减少只读热点数据跨NUMA Zone的访问,可以将读写比非常高的Page,使用Replication的方式在每个NUMA Zone的Direct内存中都复制一个副本,降低响应时间。
- 为了减少
False Sharing,监控造成大量Cache Miss的Page,并进行拆分重组。将同一CPU亲和的数据放在同一个Page中
现实
谈完了理想,我们看看现实。现实往往是残酷的,由于没有硬件级别的PMU(Performance Monitor Unit)支持,获取精准的Page访问和Cache Miss信息性能代价非常大。所以上面的理想仅仅停留在实验和论文阶段。那么在理想实现之前,我们现在该怎么办呢? 答案只有一个就是测试
实际测试 实际测试的结果最具有说服力。所谓实际测试就是把优化对象给予真实环境的压力模拟。通过对比开启和关闭HugePage时的性能差别来验证HugePage是否会带来性能提升。当然大多数应用程序,要想模拟真实环境下的运行情况是非常困难的。那么我们就可以用下面这种理论测试
理论测试 理论测试可以通过profile预估出HugePage能够带来的潜在提升。具体原理就是计算当前应用程序运行时TLB Miss导致的Page Walk成本占程序总执行时间的占比。当然这种测试方式没有把上文提到的那两种性能损失考虑进去,所以只能用于计算HugePage所能带来的潜在性能提升的上限。如果计算出来这个值非常低,那么可以认为使用HugePage则会带来额外的性能损失。具体方法见LWN上介绍的方法 具体的计算公式如下图:

五、总结
并不是所有的优化方案都是0性能损失的。充分的测试和对于优化原理的理解是一个成功优化的前提条件。
<Reference>
- Huge pages part 5: A deeper look at TLBs and costs
- About Huge Page
- TLB on Wikipedia
- Traffic Management: A Holistic Approach to Memory Placement on NUMA Systems
- Large Pages May Be Harmful on NUMA Systems