一、经典Partial page write问题?
介绍doublewrite之前我们有必要了解partial page write(部分页失效)问题。
InnoDB中有记录(Row)被更新时,先将其在Buffer Pool中的page更新,并将这次更新记录到Redo Log file中,这时候Buffer Pool中的该page就是被标记为Dirty。在适当的时候(Buffer Pool不够、Redo不够,系统闲置等),这些Dirty Page会被Checkpoint刷新到磁盘进行持久化操作。
我们知道,InnoDB的Page Size是16KB,其数据校验也是针对这16KB来计算的,将数据写入到磁盘是以Page为单位进行操作的。我们知道文件系统是以4k为单位写入,机械磁盘是以扇区(512字节)为单位写入(SSD本质上虽然没有扇区概念,但为了兼容机械盘,也搞出了这么一个512字节扇区这么一个写方式),不能保证MySQL数据页面16KB的一次性原子写。试想,在某个Dirty Page flush的过程中,发生了系统断电(或者OS崩溃),16K的数据只有8K被写到磁盘上,只有一部分写是成功的,这种现象被称为(partial page writes、torn pages、fractured writes)。
一旦partial page writes发生,那么在InnoDB恢复时就很尴尬:redo log的页大小一般设计为512个字节,因此redo log page本身不会发生break page。用redo log来解决partial write 理论上是可行的,不过 InnoDB 的 redo log 是物理逻辑日志,并不是纯物理日志,因此发生partial write后崩溃恢复过程中不能直接应用redo log。所以基于redo log进行恢复page时必须需要基于正确的Page状态上重放Redo,当前InnoDB发现break page后实际上会报错。
市场上数据库这么多,根据每个数据库系统实现的不同,其redo log可分为以下几种类型:
- 物理日志(physical logging)
物理日志是指在日志中保存一个页中发生改变的字节。物理日志的好处是其记录的是页中发生变化的字节。这样重复多次执行该日志不会导致数据发生不一致的问题。也就是该日志是幂等的,没有partial write的问题。物理日志看起来很优雅,但其最大的问题是产生的日志量相对较大。例如对一个16K大小的页进行重新整理(reorganize),那么这时产生的日志就需要16K。此外,B+树分裂这类涉及到多个页修改的操作,产生的日志同样也会非常大。
- 逻辑日志(logical logging)
其记录的是对于表的操作,这非常类似与MySQL数据库上层产生的二进制日志。由于是逻辑的,因此其日志的尺寸非常小。例如对于插入操作,其仅需类似如下的格式:<insert op, table name, record value>。
逻辑日志对于UNDO操作仅需对记录的日志操作进行逆操作。例如INSERT对应DELETE操作,DELETE对应INSERT操作。然而该日志的缺点同样非常明显,那就是在恢复时其可能无法保证数据的一致性。例如当对表进行插入操作时,表上还有其他辅助索引。当操作未全部完成时系统发生了宕机,那么要回滚上述操作可能是困难。因为,这时数据可能处在一个未知的状态。无法保证UNDO之后数据的一致性。
- 物理逻辑日志(physicallogical logging)
其结合上述两种日志的优点,其设计思想是:physical-to-a-page,logical-within-a-page(对应页是物理的,页内部的操作是逻辑的)。即根据物理页进行日志记录,根据不同的逻辑操作类型进行日志的写入。在InnoDB存储引擎中,用户可以发现多种重做日志类型的定义。到MySQL 5.6版本时,共有51种不同类型的重做日志。此外,每个重做日志是有固定的头部格式,如:
| redo_log_type | space | page_no | redo log body |
可以看到redo_log_type定义了逻辑操作的类型,space,page_no表示哪个物理页产生的日志。因此,InnoDB存储引擎的所有重做日志都是physiological logging的。对于页的整理操作,只需将redo_log_type设置为MLOG_PAGE_REORGANIZE,此时产生的日志仅10个字节(若space和offset可进行压缩,则可能会更小)。
另外,物理逻辑日志页不是完全幂等的,这取决于重做日志类型。对于MLOG_PAGE_REORGANIZE类型的重做日志其是幂等的,但是对于INSERT产生的日志其不是幂等的,因为INSERT重做日志记录的不是插入的记录,而是待插入记录的前一条记录的位置,以及与该记录的二进制diff信息(这样做是为了进行压缩,从而使得重做日志更小)。因此,physiological logging的恢复还需要进行如下的判断:
|
1 2 |
if page.lsn < log_record.lsn redo(page,log); |
现在问题很简单了,假设一个页在reorginaze后刷新到磁盘时发生了partial write的问题,那么由于重做日志中记录的仅仅是一个类型,没有原页的完整信息,因此恢复会失效。对于其他类型的重做日志,同样会存在这样的问题。即使是INSERT或者UPDATE操作产生的重做日志。
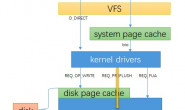
为了解决这个问题,InnoDB实现了doublewrite buffer,简单来说,就是在写数据页之前,先把这个数据页写到一块独立的物理文件位置(ibdata),然后再写到数据页。这样在宕机重启时,如果出现数据页损坏,那么在应用redo log之前,需要通过该页的副本来还原该页,然后再进行redo log重做,这就是doublewrite。doublewrite技术带给innodb存储引擎的是数据页的可靠性,下面对doublewrite技术进行解析,让大家充分理解doublewrite是如何做到保障数据页的可靠性。
二、doublewrite体系结构及工作流程?
doublewrite由两部分组成,一部分是InnoDB内存中的doublewrite buffer,大小为2M,另一部分是物理磁盘上ibdata系统表空间中大小为2MB,共128个连续的Page,既2个分区(extend)一个段(segment)。其中120个页用于批量刷新脏页(如LRU LIST刷新与FLUSH LIST刷新这两种刷新策略),另外8个页用于单页刷新(Single Page Flush)。做区分的原因是批量刷脏是后台线程做的,不影响前台线程。而单页刷新是用户线程发起的,需要尽快的刷脏页并替换出一个空闲页出来。
- 单页刷新
对于单页刷新,实际上是MySQL 5.5版本中的实现方式,做的是同步写操作,在挑出一个可以刷脏的page后,先加入到doublewrite中,刷到ibdata,然后写到用户表空间,完成后,会对该用户表空间做一次fsync操作。
单页刷新在Buffer Pool中free page不够时触发,通常由前台线程发起,由于每次单页刷新都会导致一次fsync操作,在大并发负载下,如果大量线程去做刷新,很显然会产生严重的性能下降。Percona在5.6版本中做了优化,可以选择由后台线程lru manager来做预刷,避免用户线程陷入其中。
- 批量刷新
对于批量刷脏,是在MySQL 5.7中实现的。前面说了批量的两次写,是按照刷盘策略来的,包括LRU LIST和FLUSH LIST。在两次写中,这两种刷盘策略对应的两次写空间互不干涉。同时,InnoDB自身的整个Buffer Pool分为多个Instance,每个Instance管理自身的一套两次写空间。而针对每一个Instance的每一个刷盘方法的缓存空间大小,是通过参数innodb_doublewrite_batch_size来控制的,默认值120个页面,在Debug模式下才能看见此参数。
当有需要刷新的page时,对其持有S lock,然后根据当前页面所在的instance号及刷盘类型就可以找到对应的shard缓存(每个instance中每种刷盘类型都有对应的shard缓存)。找到之后判断当前缓存是否已经满了,即是否已经达到了innodb_doublewrite_batch_size的大小,如果没有达到,则将当前页面内容追加复制到当前缓存中,这样当前页面的刷盘操作就完成了,释放block上的S锁。这里并不像单一页面刷盘那样,先写入两次写缓存空间,最后还需要立即将页面的真实内容刷人表空间,对于批量刷新来说,只需要写入缓存即可。
如果当前缓存的页面个数已经达到了innodb_doublewrite_batch_size,则说明当前缓存空间已经满了,此时不得不将当前缓存的页面写入两次写文件中,写完之后再将两次写刷新到磁盘。最后将对应的真实页面刷盘,但此时可能就是随机写入了,因为在两次写缓存中虽然是连续的,但对应的真实页面就不会是这样了。这里还需要注意,这是同步写操作,整个缓存刷新完之后,然后再唤醒后台IO线程去写数据页。当后台IO线程完成写操作后,会去清空缓存中的数据,完成写入。
现在需要注意的是,上面写入的是连续innodb_doublewrite_batch_size个页面,所以性能会比单页刷新要好的很多。在批量刷新的情况下,有可能每隔innodb_doublewrite_batch_size个页面的刷盘操作,就会出现一次等待操作,等待时间长短不太确定,但这也是在单页刷新的基础上优化过的。
如果发生了极端情况(断电),InnoDB再次启动后,发现了一个Page数据已经损坏,那么此时就可以从doublewrite buffer中进行数据恢复了。
有了doublewrite后,脏页刷新及数据恢复大致工作原理如下图(第一步应为脏页产生的redo记录log buffer,然后log buffer写入redo log file,为简化次要步骤直接连线表示):
")
查看doublewrite工作情况,可以执行命令:
|
1 2 3 4 5 6 7 8 |
mysql> show status like "%InnoDB_dblwr%"; +----------------------------+------------+ | Variable_name | Value | +----------------------------+------------+ | Innodb_dblwr_pages_written |61932183 | | Innodb_dblwr_writes |15237891 | +----------------------------+------------+ 2 rows in set (0.01 sec) |
以上数据显示,doublewrite一共写了61932183个页,一共写了15237891次,从这组数据我们可以分析,之前讲过在开启doublewrite后,每次脏页刷新必须要先写doublewrite,而doublewrite存在于磁盘上的是两个连续的区,每个区由连续的页组成,一般情况下一个区最多有64个页,所以一次IO写入应该可以最多写64个页。而根据以上我这个系统Innodb_dblwr_pages_written与Innodb_dblwr_writes的比例来看,一次大概在4个页左右,远远还没到64,所以从这个角度也可以看出,系统写入压力并不高。
如果操作系统在将页写入磁盘的过程中发送了崩溃,在恢复过程中,InnoDB存储引擎可以从工序表空间中的doublewrite中找到该页的副本,将其复制到表空间文件,再应用redo log。下面显示了一个由doublewrite进行恢复的过程:
|
1 2 3 4 5 6 7 |
090924 11:36:32 mysqld restarted 090924 11:26:33 InnoDB: Database was not shut down normally! InnoDB: Starting crash recovery. InnoDB: Reading tablespace information from the .ibd files... InnoDB: Crash recovery may have faild for some .ibd files! InnoDB: Restoring possible half-written data pages from the doublewrite. InnoDB: buffer... |
Q:为什么redo log不需要doublewrite的支持?
A:因为redolog设计页大小就是512字节,也就是磁盘IO的最小单位,所以无所谓数据损坏。
三、doublewrite的性能损耗?
至于性能问题,表面看上去,它是每个页面都写了2遍,会非常影响性能。但实际上,由于所写的页面会先缓存到内存中,因此每一部分缓存空间在满了之后才会真正地写入文件。并且doublewrite是一个连接的存储空间,所以硬盘在写数据的时候是顺序写,而不是随机写,这样性能很高。doublewrite有效利用这个特地那,所以降低并不会相差1倍,经过测试,大概5-10%左右。当然,这是针对普通磁盘。对于目前比较流行的SSD来说,随机写已经不是问题,性能影响可能更小。
doublewrite默认开启,参数skip_innodb_doublewrite虽然可以禁止使用doublewrite功能,但还是强烈建议大家使用doublewrite。避免部分写失效问题,当然,如果你的数据表空间放在本身就提供了部分写失效防范机制的文件系统上,如ZFS/FusionIO/DirectFS文件系统,在这种情况下,就可以不开启doublewrite了。
其实两次写并不是什么特性或优点,它只是一个被动解决方案而已。这个问题的本质就是磁盘在写入时,都是以512字节为单位,不能保证MySQL数据页面16KB的一次性原子写,所以才有可能产生页面断裂的问题。而目前有些厂商从硬件驱动层面做了优化,可以保证16KB(或其他配置)数据的原子性写入。如果真是这样,那么两次写就完全没有必要了,取消两次写,才是最终级优化,值得期待。
四、doublewrite在恢复的时候是如何工作的?
首先,如果是写doublewrite buffer本身失败,那么这些数据不会被写到磁盘,InnoDB此时会从磁盘载入原始的数据,然后通过InnoDB的事务日志来计算出正确的数据,重新写入到doublewrite buffer。
如果doublewrite buffer写成功的话,但是写磁盘失败,在数据库启动时,都会做数据库恢复操作。如果检测到一个页面的校验结果不一致,则此时会用到doublewrite,用doublewrite空间中的数据来恢复异常页面的数据,这也正是为了处理这样的错误而设计的。
此时的操作就很明白了,将doublewrite的数据都读出来,然后将所有这些页面写回到对应的页面中去,这样就可以保证这些页面是正确的,并且是在写入前已经更新过的最新数据。在写回对应页面中去之后,就可以在此基础上继续做数据库恢复,且不会再遇到这样的问题了,因为最后有可能产生写断裂的数据页面都已经恢复了。
五、InnoDB能否通过其他方式解决partial write?
可以,如果系统表空间文件(“ibdata文件”)位于支持原子写入的Fusion-io设备上,就能避免partial write ,可以不用doublewrite机制。还有大名鼎鼎的阿里云polardb,在底层分布式文件系统PolarFS能提供页大小(如16)KB小的原子写入,无需double write 机制来避免partial write。还有XDB的DBFS也类似实现了原子写。
可以总结数据库为了解决partial write问题,一般有4种手段:
- 事后恢复:innodb doublewirite 机制,事先存一份page的副本,当partial write发生需要恢复时,先通过page的副本来还原该page,再进行重做;
- 事后恢复:物理redo log 恢复机制,物理redo log里面存有完整的数据page,当partial write发生需要恢复时,先通过redo log page的副本来还原该page,再进行重做可以保证幂等性;
- 事先避免:底层存储来实现原子写入避免partial write;
- 事先避免:数据库的page size 设置为块设备扇区大小512字节保证原子写避免partial write,如:innodb redo log 。
下面来看下常见的存储引擎或者数据库系统他们是怎么解决partial write的。
- PostgreSQL
PG采用的是第二种方式。通过full_page_write机制,在物理redo log中写dirty page的full page解决了数据页的partial write问题。然而pg的redo log page size默认是8K的,不是512字节对齐物理磁盘block,所以理论上PG的redo log 也会存在partial write。不过redo log 的partial write并不会带来数据一致性的问题,因为假如出现了partial write说明事务未提交成功,那么崩溃恢复的时候对PG来说也是不会去恢复的。
- MongoDB WiredTiger
WiredTiger中刷脏页是通过将内存中的btree修改过的PAGE做一次checkpoint并写入持久化存储,每个btree对应磁盘上一个物理文件,btree的每个PAGE以文件里的extent形式上的page。很显然checkpoint是一个append only方式,也就是说WiredTiger会保存多个checkpoint版本。由于原page并没有被更新,所以即使发生partial write,不管从哪个版本的checkpoint开始都可以通过重演journal log来恢复来保证page的完整性。值得一提的是MongoDB 3.5.12中WiredTiger在内存和journal log中实现了in-place update,但数据写磁盘的机制并未改变,因此依然可以解决partial write。
- RocksDB & InfluxDB
存储引擎采用LSM或者TSM(类LSM)的结构,数据page采用append only方式写入,而不是像innodb或PG一样采用in-place update的方式写入page,所以即使出现了partial write,由于原page没有变更,可以通过原page重做wal log恢复来保证page的完整性。
这就是influxdb为什么不需要doublewrite原因,其实还蛮简单的。
六、MariaDB/MySQL/Facebook/Percona 5.7的改进
- MariaDB/MySQL改进
MariaDB使用参数innodb_use_atomic_writes来控制原子写行为,当打开该选项时,会使用O_DIRECT模式打表空间,通过posix_fallocate来扩展文件(而不是写0扩展),当在启动时检查到支持atomic write时,即使开启了innodb_doublewrite,也会关闭掉。
Oracle MySQL同样支持FusionIO的Atomic Write特性(Fusion-io Non-Volatile Memory (NVM) file system),对于支持原子写的文件系统,也会自动关闭doublewrite buffer。
- Facebook改进
实际上这不能算是改进,只是提供了一个新的选项。在现实场景中,宕机是非常低概率的事件。大部分情况下dblwr都是用不上的。但如果我们直接关闭dblwr,如果真的发生例如掉电宕机了,我们需要知道哪些page可能损坏了。
因此Facebook MySQL提供了一个选项,可以写page之前,只将对应的page number写到dblwr中(而不是写全page),在崩溃恢复时,先读出记录在dblwr中的page号,检查对应的数据页是否损坏,如果损坏了,那就需要从备库重新恢复该实例。
- Percona 5.7改进
Percona Server的每个版本都对InnoDB的刷脏逻辑做了不少的优化,进入5.7版本也不例外。在官方5.7中已经实现了多个Page Cleaner,我们可以把Page Cleaner配置成和buffer pool instance的个数相同,可以更好的实现并行刷脏。
但是官方版本中,Page cleaner既要负责刷FLUSH LIST,同时也要做LRU FLUSH(但每个buffer pool instance不超过innodb_lru_scan_depth)。而这两部分任务是可以独立进行的。
因此Percona Server增加了多个LRU FLUSH线程,可以更高效的进行LRU FLUSH,避免用户线程陷入single page flush状态。每个buffer pool instance拥有自己的LRU FLUSH线程和page cleaner线程。LRU FLUSH基于当前free list的长度进行自适应计算。 每个LRU线程负责自己的那个Buffer Pool。因此不同LRU FLUSH线程的繁忙程度可能是不一样的。
在解决上述问题后,buffer pool instance的并行效率大大的提升了。但是对于所有的刷脏操作,都需要走到doublewrite buffer。这意味着dblwr成为了新的瓶颈。为了解决这个问题,dblwr进行了拆分,每个buffer pool instance都有自己的dblwr区域。这样各个Lru flush线程及Page cleaner线程在做page flush时就不会相互间产生锁冲突,从而提升了系统的扩展性。
你可以通过参数来配置一个独立于ibdata之外的文件来存储dblwr,文件被划分成多个区域,分区数为bp instance的个数,每个分区的大小为2 * srv_doublewrite_batch_size,每个batch size默认配置为120个page,其中一个用于刷FLUH LIST,一个用于刷LRU。
如果fast shutdown设置为2,dblwr文件在正常shutdown时会被删除掉,并在重启后重建。
<摘之>
MYSQL innodb两次写(double write)实现解析
MySQL · 杂谈 · InnoDB Double Write Buffer那些事儿