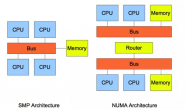
在生产环境中,尽管我们尽力避免误操作,但是还是会遇到误操作或是其他情况的出现。这时候我们就需要进行Point in time recovery了。Mongodb的point in time recovery是基于oplog进行的,所以请确保oplog的size足够大,也请确保定时有冷备份(或是延时备份)。
理论上只要我们的mongodump做得足够频繁再结合oplog,是可以保证数据库能够恢复到过去的任意一个时间点的。MMS(现在叫Cloud Manager)的付费备份也正是在利用这个原理工作。
切记:在出现问题的时候,我们第一时间要做的时保护犯罪现场,停止应用写入,保护数据库数据与状态。有可能的话,在进行恢复之前,将现在的oplog进行一次全备份,也将现在数据进行一次全备份。
根据point in time恢复的前提条件:
1)必须在oplog时间窗口期内有完整的数据备份;
2)最好在误操作之后就立马停止数据库的写入操作;
下面是通过冷备份+oplog进行point in time recovery的例子(例子仅供参考,实际中请根据情况来操作,过程需严谨)
第一步:首先创造点数据
|
1 2 3 4 |
use test for(var i = 0; i < 1000; i++) { db.foo.insert({a: i}); } |
第二步:更改点数据
|
1 |
ywnds:PRIMARY> db.foo.update({"a":999},{$set:{"a":1000}}) |
第三步:做一次完全备份
|
1 |
$ mongodump -h 127.0.0.1 --port 27017 -d test -o /backup |
第四步:插入一些数据
|
1 |
ywnds:PRIMARY> db.foo.insert({"a":2000}) |
第五步:删除一条数据(模拟误操作)
|
1 |
ywnds:PRIMARY> db.foo.remove({"a":10}) |
第六步:再次插入一条数据
|
1 |
ywnds:PRIMARY> db.foo.insert({"a":3000}) |
查看现在一共有多少条数据
|
1 2 |
ywnds:PRIMARY> db.foo.count() 1001 |
我们现在想要取消第五步操作(remove操作,假设其为误操作),但是不影响其他数据。
我们先整体备份oplog(保护犯罪现场,哈哈,防止出现其他问题,有可能的话,还可以将现在的数据进行一次备份,防止如果操作失败造成的数据问题。)
|
1 |
# mongodump --port 27017 -d local -c oplog.rs -o /tmp/oplog/ |
第一步:找到误操作语句的时间戳
首先需要查找出操作失误的步骤,我们根据条件来匹配查找,条件越多对于定位误操作语句越有效。一般操作的动作肯定知道,其二是操作的库和集合肯定知道,最后如果知道大概的时间点就更好了,但这些并不能保证100%能够找到误操作的语句。
|
1 2 3 4 5 6 7 8 9 10 11 12 |
ywnds:PRIMARY> db.oplog.rs.find({"op" : "d", "ns" : "test.foo"}).pretty() { "ts" : Timestamp(1481095782, 2), "t" : NumberLong(1), "h" : NumberLong("-8377102158449591320"), "v" : 2, "op" : "d", "ns" : "test.foo", "o" : { "_id" : ObjectId("58466e862780d8f6f6594dd0") } } |
可以拿着这个ObjectId去备份数据中验证一下。
现在已经找到了误操作的语句后,接下来就是要找出完整备份之后和删除(误操作)之前的所有操作。
第二步:找到备份的最后一条语句的操作记录的时间戳
|
1 2 |
$ bsondump /backup/test/foo.bson | tail -n1 {"_id":{"$oid":"58466e872780d8f6f65951ad"},"a":1000.0} |
|
1 2 3 |
ywnds:PRIMARY> db.oplog.rs.find({"ns" : "test.foo","o":{"_id" : ObjectId("58466e872780d8f6f65951ad"),"a":1000}}) { "ts" : Timestamp(1481094522, 1), "t" : NumberLong(1), "h" : NumberLong("-7286476219427328778"), "v" : 2, "op" : "u", "ns" : "test.foo", "o2" : { "_id" : ObjectId("58466e872780d8f6f65951ad") }, "o" : { "_id" : ObjectId("58466e872780d8f6f65951ad"), "a" : 1000 } } |
PS:我个人感觉使用文档去查还是精确的,操作一般无非就是insert或update,根据其文档就可以查出这条语句的最后一步操作。
第三步:根据误操作语句的时间戳和备份数据最后一条操作语句的时间戳找到这中间的所有操作语句
|
1 2 3 4 5 6 7 8 9 10 11 12 13 |
ywnds:PRIMARY> db.oplog.rs.find({ts:{$lt:Timestamp(1481095782, 2),$gt:Timestamp(1481094522, 1)}}).pretty() { "ts" : Timestamp(1481095782, 1), "t" : NumberLong(1), "h" : NumberLong("-6509530327776617288"), "v" : 2, "op" : "i", "ns" : "test.foo", "o" : { "_id" : ObjectId("5847ba662780d8f6f65951b2"), "a" : 2000 } } |
由于生产环境中会是很多操作,所以将其dump出来。
|
1 |
$ mongodump --port 27017 -d local -c oplog.rs -q '{ts:{$lt:Timestamp(1481095782, 2),$gt:Timestamp(1481094522, 1)}}' -o /tmp/restore-1 |
第四步:再根据误操作时的时间戳找出之后的操作语句
|
1 2 3 4 5 6 7 8 9 10 11 12 13 |
ywnds:PRIMARY> db.oplog.rs.find({ts:{$gt:Timestamp(1481095782, 2)}}).pretty() { "ts" : Timestamp(1481095783, 1), "t" : NumberLong(1), "h" : NumberLong("-7552219668757596741"), "v" : 2, "op" : "i", "ns" : "test.foo", "o" : { "_id" : ObjectId("5847ba672780d8f6f65951b3"), "a" : 3000 } } |
同样将其dump出来
|
1 |
$ mongodump --port 27017 -d local -c oplog.rs -q '{ts:{$gt:Timestamp(1481095782, 2)}}' -o /backup/restore-2 |
第五步:进行数据恢复
现在有了一次完整备份加上oplog提取的操作就可以进行数据的恢复了。
|
1 2 |
ywnds:PRIMARY> db.foo.drop() true |
做前期准备,把restore-1中的oplog.rs.bson复制到完整备份目录下,名称为oplog.bson。
|
1 2 3 4 |
$ cp -fr /tmp/restore-1/local/oplog.rs.bson /backup/oplog.bson $ ll /backup drwxr-xr-x. 2 root root 4096 Dec 7 19:43 test -rwxr-xr-x. 1 root root 210 Dec 7 19:43 oplog.bson |
然后使用mongorestore进行完整备份数据的恢复,并且加上–oplogReplay参数会同时把resetore-1提取的操作进行重放(恢复第四步操作)。
|
1 2 3 4 5 6 7 8 9 10 11 12 |
$ mongorestore --port 27017 --oplogReplay /backup/ 2016-12-07T19:18:59.389+0800 building a list of dbs and collections to restore from /backup dir 2016-12-07T19:18:59.392+0800 reading metadata for test.foo from /backup/test/foo.metadata.json 2016-12-07T19:18:59.392+0800 reading metadata for test.oplog.rs from /backup/test/oplog.rs.metadata.json 2016-12-07T19:18:59.392+0800 restoring test.oplog.rs from /backup/test/oplog.rs.bson 2016-12-07T19:18:59.446+0800 restoring test.foo from /backup/test/foo.bson 2016-12-07T19:18:59.495+0800 no indexes to restore 2016-12-07T19:18:59.496+0800 finished restoring test.oplog.rs (6 documents) 2016-12-07T19:18:59.688+0800 restoring indexes for collection test.foo from metadata 2016-12-07T19:18:59.689+0800 finished restoring test.foo (1000 documents) 2016-12-07T19:18:59.689+0800 replaying oplog 2016-12-07T19:18:59.693+0800 done |
进入到mongodb查看数据恢复情况。
|
1 2 3 4 5 6 7 8 |
ywnds:PRIMARY> db.foo.count() 1001 ywnds:PRIMARY> db.foo.find({"a":2000}) { "_id" : ObjectId("5847ba662780d8f6f65951b2"), "a" : 2000 } ywnds:PRIMARY> db.foo.find({"a":10}) { "_id" : ObjectId("58466e862780d8f6f6594dd0"), "a" : 10 } ywnds:PRIMARY> db.foo.find({"a":3000}) ywnds:PRIMARY> |
可以看出误操作之前的数据都已经恢复,只有误操作之后的数据还没有。所以接下来就可以接着来恢复误操作之后的数据(恢复第六步操作)。
再重新备份一次,然后同样把restore-2中的oplog.rs.bson复制到备份目录。
|
1 2 3 4 5 6 |
$ mv /backup/* /tmp/ $ mongodump -h 127.0.0.1 --port 27017 -d test -o /backup 2016-12-07T19:36:18.917+0800 writing test.foo to 2016-12-07T19:36:18.917+0800 writing test.oplog to 2016-12-07T19:36:18.918+0800 done dumping test.oplog (2 documents) 2016-12-07T19:36:18.922+0800 done dumping test.foo (1001 documents) |
|
1 |
$ cp -fr /tmp/restore-2/local/oplog.rs.bson /backup/oplog.bson |
然后再次使用mongorestore进行恢复。
|
1 2 |
ywnds:PRIMARY> db.foo.drop() true |
|
1 |
$ mongorestore --port 27017 --oplogReplay /backup/ |
最后再次进入到mongo中查看误操作之后的数据是否存在。
|
1 2 3 4 |
ywnds:PRIMARY> db.foo.count() 1002 ywnds:PRIMARY> db.foo.find({"a":3000}) { "_id" : ObjectId("5847ba672780d8f6f65951b3"), "a" : 3000 } |
至此,我们整个的point in time recovery便完成了。对于恢复工具的使用可以看:MongoDB数据备份和恢复工具详解。
另外Eshu用GO写了一个point in time recovery工具,可以玩玩:https://github.com/eshujiushiwo/mopre。