一、FTWRL
FLUSH TABLES WITH READ LOCK(FTWRL),该命令属于 MySQL Server 命令,多用于备份的时候对全局表进行锁定来获取 binlog 信息。虽然持有时间很短,但容易被大操作堵塞造成备份不能完成。由于 FTWRL 总共需要持有两把全局的 MDL(Metadata Data Lock)锁,并且还需要关闭所有表对象,因此这个命令的杀伤性很大,执行命令时容易导致库 hang 住。如果是主库,则业务无法正常访问;如果是备库,则会导致 SQL 线程卡住,主备延迟。本文将详细介绍 FTWRL 到底做了什么操作,每个操作的对库的影响,以及操作背后的原因。
二、原理分析
sql_parse.cc
实际上这部分我们可以在函数 mysql_execute_command 寻找 case SQLCOM_FLUSH 的部分,实际上主要调用函数为 reload_acl_and_cache,其中核心部分为:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 |
bool reload_acl_and_cache(THD *thd, unsigned long options, TABLE_LIST *tables, int *write_to_binlog) { ... if (options & (REFRESH_TABLES | REFRESH_READ_LOCK)) { if ((options & REFRESH_READ_LOCK) && thd) { if (thd->locked_tables_mode) { my_error(ER_LOCK_OR_ACTIVE_TRANSACTION, MYF(0)); return 1; } /* 写入binlog可能导致死锁,因为我们不记录UNLOCK TABLES */ tmp_write_to_binlog= 0; if (thd->global_read_lock.lock_global_read_lock(thd)) // 加 MDL GLOBAL 级别S锁 return 1; // Killed if (close_cached_tables(thd, tables, // 关闭表操作释放 share 和 cache ((options & REFRESH_FAST) ? FALSE : TRUE), thd->variables.lock_wait_timeout)) // 等待时间受lock_wait_timeout影响 { /* 注意: my_error() 已经被 close_cached_tables() 中的 reopen_tables() 调用了 */ result= 1; } if (thd->global_read_lock.make_global_read_lock_block_commit(thd)) // MDL COMMIT 锁 { /* Don't leave things in a half-locked state */ thd->global_read_lock.unlock_global_read_lock(thd); return 1; } } } } |
FTWRL做了什么操作?
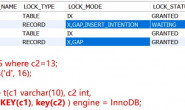
第一步:加 MDL LOCK 类型为 GLOBAL 级别为 S 锁。如果出现等待状态为 ‘Waiting for global read lock’。注意 select 语句不会上 GLOBAL 级别锁,但是 DML/DDL/FOR UPDATE 语句会上 GLOBAL 级别的 IX 锁,IX 锁和 S 锁不兼容会出现这种等待。
下面是这个兼容矩阵:
|
1 2 3 4 5 6 7 8 |
| Type of active | Request | scoped lock | type | IS(*) IX S X | ---------+------------------+ IS | + + + + | IX | + + - - | S | + - + - | X | + - - - | |
第二步:推进全局表缓存版本。源码中就是一个全局变量 refresh_version++。然后释放没有使用的 TABLE 和 TABLE_SHARE 缓存。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 |
bool close_cached_tables(THD *thd, TABLE_LIST *tables, bool wait_for_refresh, ulong timeout) { bool result= FALSE; bool found= TRUE; struct timespec abstime; table_cache_manager.lock_all_and_tdc(); if (!tables) { // 推进全局表缓存版本 refresh_version++; // 释放所有未使用的TABLE和TABLE_SHARE实例 table_cache_manager.free_all_unused_tables(); // 释放没有被上述循环隐式释放的TABLE_SHARE while (oldest_unused_share->next) (void) my_hash_delete(&table_def_cache, (uchar*) oldest_unused_share); } else {...} table_cache_manager.unlock_all_and_tdc(); } |
第三步:可自行参考函数 close_cached_tables 函数。
每个表在内存中都有一个 table_cache,不同表的 cache 对象通过 hash 链表维护。访问 cache 对象通过 LOCK_open 互斥量保护,每个会话打开的表时,引用计数 share->ref_count++,关闭表时,都会去对引用计数 share->ref_count–。若发现是 share 对象的最后一个引用(share->ref_count==0),并且 share 有 old_version,则将 table_def_cache 从 hash 链表中摘除,调用 free_table_share 进行处理。
关键函数关闭表流程如下:
- 关闭所有未使用的表对象
- 更新全局字典的版本号
- 对于在使用的表对象,逐一检查,若表还在使用中,调用 MDL_wait::timed_wait 进行等待
- 将等待对象关联到 table_cache 对象中
- 继续遍历使用的表对象
- 直到所有表都不再使用,则关闭成功。
清理表缓存函数调用
mysql_execute_command->reload_acl_and_cache->close_cached_tables->TABLE_SHARE::wait_for_old_version->MDL_wait::timed_wait->inline_mysql_cond_timedwait
会话操作表流程:
- 打开表操作,若发现还有 old_version,则进行等待
- share->ref_count++
- 操作完毕,检查 share->ref_count– 是否为 0
- 若为 0,并且检查发现有新版本号,则认为 cache 对象需要重载
- 将 cache 对象摘除,调用 MDL_wait::set_status 唤醒所有等待的线程。
关闭表对象函数调用
dispatch_command->mysql_parse->mysql_execute_command->close_thread_tables->close_open_tables->close_thread_table->intern_close_table->closefrm->release_table_share->my_hash_delete->table_def_free_entry->free_table_share
更具体的关闭表的操作和释放 table 缓存的部分包含在函数 close_cached_tables 中,我就不详细写了。但是我们需要明白 table 缓存实际上包含两个部分:
第四步:判断是否有正在占用的 table 缓存,如果有则等待,等待占用者释放。等待状态为’Waiting for table flush’。这一步会去判断 table 缓存的版本和全局表缓存版本是否匹配,如果不匹配则等待。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 |
bool close_cached_tables(THD *thd, TABLE_LIST *tables, bool wait_for_refresh, ulong timeout) { ... while (found && !thd->killed) { TABLE_SHARE *share; found= FALSE; mysql_ha_flush(thd); mysql_mutex_lock(&LOCK_open); if (!tables) { for (uint idx=0 ; idx < table_def_cache.records ; idx++) { share= (TABLE_SHARE*) my_hash_element(&table_def_cache, idx); // 寻找整个table cache shared hash结构 if (share->has_old_version()) // 如果版本和当前的refresh_version版本不一致 { found= TRUE; break; // 跳出第一层查找 是否有老版本 存在 } } } else { for (TABLE_LIST *table= tables; table; table= table->next_local) { share= get_cached_table_share(thd, table->db, table->table_name); if (share && share->has_old_version()) { found= TRUE; break; } } } if (found) // 如果找到老版本,需要等待 { /* 下面的方法暂时解锁LOCK_open并释放了共享的内存 */ if (share->wait_for_old_version(thd, &abstime, MDL_wait_for_subgraph::DEADLOCK_WEIGHT_DDL)) { mysql_mutex_unlock(&LOCK_open); result= TRUE; goto err_with_reopen; } } mysql_mutex_unlock(&LOCK_open); } } |
而等待的结束就是占用 table 缓存的占用者释放,这个释放操作存在于函数 close_thread_table 中,
最终会调用函数 MDL_wait::set_status 将 FTWRL 唤醒,也就是说对于正在占用的 table 缓存释放者不是 FTWRL 会话而是占用者自己。不管怎么样最终整个 table 缓存将会被清空,如果经过 FTWRL 后去查看 Open_table_definitions 和 Open_tables 将会发现重新计数了。下面是唤醒函数的代码,也很明显:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 |
bool MDL_wait::set_status(enum_wait_status status_arg) open_table { bool was_occupied= TRUE; mysql_mutex_lock(&m_LOCK_wait_status); if (m_wait_status == EMPTY) { was_occupied= FALSE; m_wait_status= status_arg; mysql_cond_signal(&m_COND_wait_status);//唤醒 } mysql_mutex_unlock(&m_LOCK_wait_status);//解锁 return was_occupied; } |
第五步:加 MDL LOCK 类型 COMMIT 级别为 S 锁。如果出现等待状态为‘Waiting for commit lock’。如果有大事务的提交很可能出现这种等待。
- 关闭所有的表重新打开,先释放table cache(包含TABLE_SHARED),然后重新加载生成table cache。
常见操作与FTWRL兼容性?
- DML\FOR UPDATE:需要获取GLOBAL的IX锁持有到语句结束,但是TABLE MDL持有到事务结束一般为(MDL_SHARED_WRITE(SW) ),DML提交的时候会持有COMMIT的IX锁。
- SELECT:不需要GLOBAL的IX锁,但是TABLE级别的MDL需要持有到事务结束,一般为(MDL_SHARED_READ(SR))。
- DDL: 需要获取GLOBAL的IX锁到语句结束,TABLE MDL多变。
如果FLWRL发出之前已经有一个Query:select count(*) from tb,那么FTWRL也得等待(show processlist可以看到waiting for table flush)。长时间的select堵塞FTWRL, 因为FTWRL要关闭所有的表,如果有活跃的语句正在执行,table cache不能清空,因此需要等待。实际上即便是flush tables也不能在有语句执行的时候执行同样需要等待。
由于FTWRL主要被备份工具使用,后面会详细解释每个步骤的作用,以及存在的必要性。FTWRL中的第1和第3步都是通过MDL锁实现,关于MDL的实现,我之前总结了MDL锁的文章,这里主要介绍清理表缓存的流程。
三、关闭表导致业务库堵住的典型场景
假设有3个会话,会话A执行大查询,访问t表;然后一个备份会话B正处于关闭表阶段,需要关闭表t;随后会话C也请求访问t表。三个会话按照这个顺序执行,我们会发现备份会话B和会话C访问t表的线程都处于“waiting for table flush”状态。这就是关闭表引起的,这个问题很严重,因为此时普通的select查询也被堵住了。下面简单解释下原因:
1. 会话A打开表t,执行中……;
2. 备份会话B需要清理表t的cache,更新版本号(refresh_version++);
3. 会话B发现表t存在旧版本(version != refresh_version),表示还有会话正在访问表t,等待,加入share对象的等待队列;
4. 后续会话C同样发现存在旧版本(version != refresh_version),等待,加入share对象的等待队列;
5. 大查询执行完毕,调用free_table_share,唤醒所有等待线程。
|
1 2 3 4 5 |
free_table_share //逐一唤醒所有等待的线程 { while ((ticket= it++)) ticket->get_ctx()->m_wait.set_status(MDL_wait::GRANTED); } |
第4步与第5步之间,所有的访问该表的会话都处于“waiting for table flush”状态,唯有大查询结束后,等待状态才能解除。
四、主备切换场景
在生产环境中,为了容灾一般MySQL服务都由主备库组成,当主库出现问题时,可以切换到备库运行,保证服务的高可用。在这个过程中有一点很重要,避免双写。因为导致切换的场景有很多,可能是因为主库压力过大hang住了,也有可能是主库触发mysql bug重启了等。当我们将备库写开启时,如果老主库活着,一定要先将其设置为read_only状态。“set global read_only=1”这个命令实际上也和FTWRL类似,也需要上两把MDL,只是不需要清理表缓存而已。如果老主库上还有大的更新事务,将导致set global read_only hang住,设置失败。因此切换程序在设计时,要考虑这一点。
关键函数:fix_read_only
1. lock_global_read_lock(),避免新的更新事务,阻止更新操作。
2. make_global_read_lock_block_commit,避免活跃的事务提交。
五、FTWRL与备份
MySQL的备份方式,主要包括两类,逻辑备份和物理备份,逻辑备份的典型代表是mysqldump,物理备份的典型代表是extrabackup。根据备份是否需要停止服务,可以将备份分为冷备和热备。冷备要求服务器关闭,这个在生产环境中基本不现实,而且也与FTWRL无关,这里主要讨论热备。Mysql的架构支持插件式存储引擎,通常我们以是否支持事务划分,典型的代表就是myisam和innodb,这两个存储引擎分别是早期和现在mysql表的默认存储引擎。我们的讨论也主要围绕这两种引擎展开。对于innodb存储引擎而言,在使用mysqldump获取一致性备份时,我们经常会使用两个参数,–single-transaction和–master-data,前者保证innodb表的数据一致性,后者保证获取与数据备份匹配的一致性位点,主要用于搭建复制。现在使用MySQL主备集群基本是标配,所以也是必需的。对于myisam,就需要通过–lock-all-tables参数和–master-data来达到同样的目的。
我们在来回顾下FTWRL的3个步骤:
1. 上全局读锁
2. 清理表缓存
3. 上全局COMMIT锁
第一步的作用是堵塞更新,备份时,我们期望获取此时数据库的一致状态,不希望有更多的更新操作进来。对于innodb引擎而言,其自身的MVCC机制,可以保证读到老版本数据,因此第一步对它使多余的。第二步,清理表缓存,这个操作对于myisam有意义,关闭myisam表时,会强制要求表的缓存落盘,这对于物理备份myisam表是有意义的,因为物理备份是直接拷贝物理文件。对于innodb表,则无需这样,因为innodb有自己的redo log,只要记录当时LSN,然后备份LSN以后的redo log即可,当然物理备份工具也会做刷新redo log这个步骤,保证innodb表数据一致。第三步,主要是保证能获取一致性的binlog位点,这点对于myisam和innodb作用是一样的。
所以总的来说,FTWRL对于innodb引擎而言,最重要的是获取一致性位点,前面两个步骤是可有可无的,因此如果业务表全部是innodb表,这把大锁从原理上来讲是可以拆的,而且Percona公司也确实做了这样的事情,具体大家可以参考blog链接。此外,官方版本的5.5和5.6对于mysqldump做了一个优化,主要改动是,5.5备份一个表,锁一个表,备份下一个表时,再上锁一个表,已经备份完的表锁不释放,这样持续进行,直到备份完成才统一释放锁。5.6则是备份完一个表,就释放一个锁,实现主要是通过innodb的保存点机制。相关的bug可以参考链接:http://bugs.mysql.com/bug.php?id=71017。
<参考>
https://www.jianshu.com/p/9007883b58b8
https://www.jianshu.com/p/2397ccc8de83