一、MySQL主从复制过滤
- 库级过滤
在评估复制选项时,从服务器首先检查是否存在可应用的复制选项replicate-do-db或 replicate-ignore-db。当使用binlog-do-db或 binlog-ignore-db过程相似,但它们属于在主库上检查选项。
主库支持的过滤选项
|
1 2 3 4 5 |
# 仅将指定库的相关修改操作记入二进制日志(白名单) binlog-do-db = DB_NAME # 忽略指定库的相关操作记录二进制日志,其余的都记入二进制日志(黑名单) binlog-ignore-db = DB_NAME |
PS: 一般不再主服务器上过滤,虽然可以减少主的开销,但这样会导致二进制日志不完整。
从库支持的过滤选项
|
1 2 3 4 5 |
# 基于库做白名单过滤; replicate-do-db = DB_NAME # 基于库做黑名单过滤; replicate-ignore-db = DB_NAME |
一般在从服务器上过滤,但是这样并不会减少主往从复制数据占用带宽。
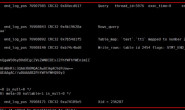
检查匹配的数据库取决于正在处理的语句的二进制日志格式,如果使用 ROW 格式记录了该语句,则要更改数据的数据库是选中的数据库。如果使用 STATEMENT 格式记录了该语句,则默认数据库(用 USE 语句指定)是选中的数据库。
注意:只有 DML 语句可以使用 ROW 格式记录,DDL 语句始终以 STATEMENT 形式记录,即使是
binlog_format=ROW。因此,所有的 DDL 语句总是按照基于 STATEMENT 的复制规则进行过滤,这意味着你在主库执行 SQL 时必须先使用USE语句显式选择缺省数据库,以便应用 DDL 语句。不然当从库使用复制过滤选项时就可能会出现异常情况,比如你会发现由于你在主库执行 SQL(CREATE TABLE db.table …)没有使用 USE 语句时,你的 DDL 语句无法正常在从库执行,而 DML 却可以正常执行,导致从库异常。
库级过滤规则如下图所示:

重要:在此阶段允许的语句尚未实际执行,在对所有表级选项 (如果有) 进行检查之前,不会执行该语句, 并且该过程的结果为允许执行该语句。
- 表级过滤
表级过滤选项,只能在从库设置。
|
1 2 3 4 5 6 7 8 9 |
# 基于表做白名单过滤,先在本地创建库,如果有多个表就需要多次使用该选项; replicate-do-table = db.table # 基于表做黑名单过滤,先在本地创建库,如果有多个表就需要多次使用该选项; replicate-ignore-table = db.table # 基于表做过滤时支持使用%和_; replicate-wild-do-table = db.% replicate-wild-ignore-table = db.tb_ |
对于表级过滤,只有在满足以下两个条件之一的情况下,从服务器才会检查并评估表级过滤选项:
1. 没有找到匹配的数据库选项。
2. 找到了一个或多个数据库选项,根据前一节中描述的规则评估其达到“执行”条件。
首先,作为初步条件,从库检查是否启用基于 STATEMENT 的复制。如果是这样,并且语句发生在一个存储的函数中,则从库执行语句并退出。如果启用了基于 ROW 的复制,从库设备不知道主库设备上存储的功能是否发生了语句,所以此条件不适用。
注意:对于基于 STATEMENT 的复制,复制事件表示语句(组成给定事件的所有更改都与单个 SQL 语句关联); 对于基于 ROW 的复制,每个事件表示单个表行中的更改(因此 UPDATE mytable SET mycol = 1 单个语句可能会产生许多基于 ROW 的事件)。从事件角度来看,检查表选项的过程对于基于 ROW 和基于 STATEMENT 的复制都是相同的。
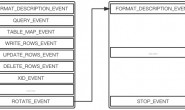
达到这一点后,如果没有表选项,从库设备只执行所有事件。如果有任何replicate-do-table或replicate-wild-do-table选项,则该事件必须与其中的一个匹配,如果要执行的话。否则,它被忽略。如果有任何replicate-ignore-table或replicate-wild-ignore-table选项,则执行所有事件,除了那些匹配任何这些选项的事件。下图说明了此过程。
表级过滤规则如下图所示:

注意:如果单个SQL语句对replicate-do-table或replicate-wild-do-table选项所包含的表以及另一个由replicate-ignore-table或replicate-wild-ignore-table选项忽略的表进行操作,则基于STATEMENT的复制将停止。从机必须执行或忽略完整的语句(它构成一个复制事件),并且它不能从逻辑上做到这一点。这也适用于DDL语句的基于ROW的复制,因为DDL语句总是记录为STATEMENT,而不考虑有效的日志格式。可以更新包含的表和被忽略的表并且仍然可以成功复制的唯一语句类型是DML语句,该语句已记录binlog_format=ROW。
二、复制规则应用
下表中给出了一些典型的复制过滤器规则类型组合:
| 条件(选项类型) | 结果 |
|---|---|
| 没有–replicate-*选项时 | 从服务器执行从主机接收到的所有事件。 |
| 只有–replicate-*-db选项,但没有表级选项时 | 从服务器使用库级选项接受或忽略事件,它执行这些选项允许的所有事件,因为没有表级限制。 |
| 只有–replicate-*-table 选项,但没有库级选项时 | 所有事件都在数据库检查阶段被接受,因为没有库级条件,从服务器只根据表选项执行或忽略事件。 |
| 库和表选项组合时 | 从服务器使用库级选项接受或忽略事件,然后根据表选项评估这些选项所允许的所有事件。这有时会导致看起来违反直觉的结果,这可能会有所不同,具体取决于你使用的是基于STATEMENT的复制还是基于ROW的复制,下面有例子。 |
下面是一个复杂的例子,在这个例子中,检查了基于 STATEMENT 和基于 ROW 格式的结果。
假设我们在主库上有 db1.tbl1 和 db2.tbl2 表,并且从服务器正在运行,但有以下选项(并且没有其他复制过滤选项):
|
1 2 |
replicate-ignore-db = db1 replicate-do-table = db2.tbl2 |
现在我们在主上执行以下语句:
|
1 2 |
USE db1; INSERT INTO db2.tbl2 VALUES (1); |
执行语句到了从库上的结果根据二进制日志格式而有很大差异,在任何情况下都可能与初始预期不符。
基于STATEMENT的复制:该USE语句db1成为默认数据库,因此被replicate-ignore-db选项匹配。并且INSERT语句被忽略,表级选项未被选中。
基于ROW的复制:当使用基于行的复制时,默认数据库对从库读取数据库选项的方式没有影响。因此,该USE语句在replicate-ignore-db选项处理方式上没有区别:由该选项指定的数据库与INSERT语句更改数据的数据库不匹配,因此从库程序继续检查表选项。指定replicate-do-table的表匹配要更新的表,并插入行。
另外需要注意的是,不管是做白名单还是黑名单,如果有多个库或者多个表的话,那么就需要写多个匹配规则,如下:
|
1 2 3 |
replicate-do-db = DB_NAME replicate-do-db = DB_NAME .... |
如果你理解了上面介绍的库级和表级过滤的运作机制,那么应该能明白不管在做白名单或黑名单时,表的过滤并不能干预库,什么意思呢?比如你只想复制 test 库下的 test 表,如果你配置如下:
|
1 |
replicate-do-table = test.test |
这么配置的话并不能达到你的需求,这个的意思是对于 test 库仅仅进行 test 表的复制,当然其他库的表也不会复制,但是会复制其他的库。
正确配置应该如下:
|
1 2 |
replicate-do-db = test replicate-do-table = test.test |
这样才是仅仅复制 test 库下的 test 表。但是这样配置又会有别的问题,如下本人生产案例。
生产案例:最后给一个本人生产中遇到的问题,主库 binlog_format=ROW,从库设置库级过滤选项 replicate-do-db = sbtest。然后在主库执行 DML 语句时可以正常同步到从库,但是执行 DDL 时由于没有使用USE设置默认库导致无法同步到从库,这个问题的原因前面说的很清楚了。但是由于刚开始本人不知道是复制过滤导致的,经过了多番测试才确定是这个问题,也可以查看 Bug#77673#(https://bugs.mysql.com/bug.php?id=77673)。目前解决方案是把库级过滤选项
replicate-do-db = sbtest替换成表级过滤选项replicate-wild-do-table = sbtest.%来解决。目前看来使用replicate-wild-do-table = sbtest.%来设置库级过滤跟replicate-do-db = sbtest效果一样,并且不需要设置默认库。
三、MySQL 5.7动态设置从库复制过滤
从MySQL 5.7.3开始支持在从库进行复制过滤了,使用语法如下:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 |
CHANGE REPLICATION FILTER filter[, filter][, ...] filter: REPLICATE_DO_DB = (db_list) | REPLICATE_IGNORE_DB = (db_list) | REPLICATE_DO_TABLE = (tbl_list) | REPLICATE_IGNORE_TABLE = (tbl_list) | REPLICATE_WILD_DO_TABLE = (wild_tbl_list) | REPLICATE_WILD_IGNORE_TABLE = (wild_tbl_list) | REPLICATE_REWRITE_DB = (db_pair_list) db_list: db_name[, db_name][, ...] tbl_list: db_name.table_name[, db_table_name][, ...] wild_tbl_list: 'db_pattern.table_pattern'[, 'db_pattern.table_pattern'][, ...] db_pair_list: (db_pair)[, (db_pair)][, ...] db_pair: from_db, to_db |
里面的参数和含义与上面介绍的相同,不同就是可以动态配置了,并且支持一个参数设置多个过滤对象了。下面给一个配置样例:
|
1 |
CHANGE REPLICATION FILTER REPLICATE_DO_DB = (db1, db2), REPLICATE_DO_DB = (db3, db4); |
四、MySQL 8.0动态多通道复制过滤
从 MySQL 5.7 推出多源复制后,一直不支持针对每个源的复制过滤,也很是尴尬。带来的一个问题就是,你的源不能有同名库,不然你只能全局过滤掉了。好在,现在这个特性已经有了。
在 MySQL 8 版本中也已经支持了针对多源情况下,使用 FOR CHANNEL 通道子句在复制通道上设置复制过滤器:
|
1 2 |
CHANGE REPLICATION FILTER filter[, filter][, ...] [, ....] [ FOR CHANNEL channel] |
<参考>
https://dev.mysql.com/doc/refman/5.7/en/change-replication-filter.html
https://dev.mysql.com/doc/refman/8.0/en/change-replication-filter.html