虚拟化
云计算现在已经非常成熟了,而虚拟化是构建云计算基础架构不可或缺的关键技术之一。 云计算的云端系统, 其实质上就是一个大型的分布式系统。 虚拟化通过在一个物理平台上虚拟出更多的虚拟平台, 而其中的每一个虚拟平台则可以作为独立的终端加入云端的分布式系统。 比起直接使用物理平台, 虚拟化在资源的有效利用、 动态调配和高可靠性方面有着巨大的优势。 利用虚拟化, 企业不必抛弃现有的基础架构即可构建全新的信息基础架构,从而更加充分地利用原有的IT投资。
虚拟化技术
虚拟化是一个广义的术语,是指计算元件在虚拟的基础上而不是真实的基础上运行,是一个为了简化管理、优化资源的解决方案。
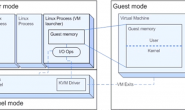
在X86平台虚拟化技术中,新引入的虚拟化层通常称为虚拟机监控器(Virtual MachineMonitor, VMM), 也叫做Hypervisor。 虚拟机监控器运行的环境,也就是真实的物理平台,称之为宿主机。而虚拟出来的平台通常称为客户机,里面运行的系统对应地也称为客户机操作系统,如下图:
")
1974年,Popek和Goldberg在一篇论文中定义了“经典虚拟化(Classical virtualization)”的基本需求,他们认为,一款真正意义上的VMM至少要符合三个方面的标准:
- 等价执行(Equivalient execution):除了资源的可用性及时间上的不同之外,程序在虚拟化环境中及真实环境中的执行是完全相同的。
- 性能(Performance):指令集中的大部分指令要能够直接运行于CPU上。
- 安全(Safety):VMM要能够完全控制系统资源。
虚拟化技术有很多种实现方式, 比如软件虚拟化和硬件虚拟化, 再比如半虚拟化和全虚拟化。 下面将针对每种实现方式做一个简单的介绍。
CPU虚拟化技术实现
一、软件虚拟化和硬件虚拟化
1)虚拟化—软件方案
纯软件虚拟化, 顾名思义, 就是用纯软件的方法在现有的物理平台上(往往并不支持硬件虚拟化) 实现对物理平台访问的截获和模拟。常见的软件虚拟机例如QEMU,它是通过纯软件来仿真X86平台处理器的取指、解码和执行,客户机的指令并不在物理平台上直接执行。由于所有的指令都是软件模拟的,因此性能往往比较差,但是可以在同一平台上模拟不同架构平台的虚拟机。
VMWare的软件虚拟化则使用了动态二进制翻译(BT)的技术,与QEMU这种模拟的方式不同,BT是一种加速虚拟化的方案之一,另一种常见的虚拟化加速方案就是硬件辅助虚拟化技术。BT就是在虚拟机监控机可控制的范围内,允许客户机的指令在物理平台上直接运行。但是,客户机指令在运行前会被虚拟机监控机扫描,其中突破虚拟机监控机限制的指令会被动态替换为可以在物理平台上直接运行的安全指令,或者替换为对虚拟机监控器的软件调用。这样做的好处是比纯软件模拟性能有大幅的提升(模拟其根本就是通过一个软件做出一个假的,可以是不存在的;而虚拟是把这个设备通过某种切割或其他方式虚拟出去提供一定程度的服务), 但是也同时失去了跨平台虚拟化的能力。
有了BT技术后,Guest的用户空间运行在CPU ring 3上,而Guest的内核空间运行在了CPU ring 1上,Host的内核空间运行在CPU ring 0上。BT就监控在CPU ring 1上,随时将Guest内核的调用给转换为特权指令调用。当然CPU ring 1并没有被使用,BT这种技术让虚拟化性能得到了大大的提升。但是BT有一个大大的缺点就是无法跨平台,使用QEMU这种模拟器不管底层硬件是什么,能模拟各种CPU架构平台,如PowerPC、ARM等;但是BT却无法做到这点,BT强烈依赖底层架构,比如底层是X86的那么只能创建X86 CPU的虚拟机。
在纯软件虚拟化解决方案中,VMM在软件套件中的位置是传统意义上操作系统所处的位置,而操作系统的位置是传统意义上应用程序所处的位置, 这种转换必然会增加系统的复杂性。软件堆栈的复杂性增加意味着,这些环境难于管理,因而会加大确保系统可靠性和安全性的困难。
2) 虚拟化—硬件方案
硬件辅助虚拟化(HVM),简而言之,就是物理平台本身提供了对特殊指令的截获和重定向的硬件支持,甚至,新的硬件会提供额外的资源来帮助软件实现对关键硬件资源的虚拟化,从而提升性能。可以理解为CPU额外增加了一个ring -1环专门提供给虚拟机运行的。以X86平台的虚拟化为例,支持虚拟技术的X86 CPU带有特别优化过的指令集来控制虚拟过程,通过这些指令集,VMM会很容易将客户机置于一种受限制的模式下运行,一旦客户机试图访问物理资源,硬件会暂停客户机的运行,将控制权交回给VMM处理。VMM还可以利用硬件的虚拟化增强机制,将客户机在受限模式下对一些特定资源的访问,完全由硬件重定向到VMM指定的虚拟资源,整个过程不需要暂停客户机的运行和VMM软件的参与。
由于虚拟化硬件可提供全新的架构,支持操作系统直接在上面运行,无需进行二进制转换,减少了相关的性能开销,极大简化了VMM 设计,进而使VMM能够按通用标准进行编写, 性能更加强大。
需要说明的是, 硬件虚拟化技术是一套解决方案。完整的情况需要CPU、主板芯片组、BIOS和软件的支持,例如VMM软件或者某些操作系统本身。即使只是CPU支持虚拟化技术,在配合VMM软件的情况下,也会比完全不支持虚拟化技术的系统有更好的性能。鉴于虚拟化的巨大需求和硬件虚拟化产品的广阔前景,Intel一直都在努力完善和加强自己的硬件虚拟化产品线。自2005年末,Intel便开始在其处理器产品线中推广应用Intel Virtualization Technology(IntelVT)虚拟化技术,发布了具有IntelVT虚拟化技术的一系列处理器产品,包括桌面的Pentium和Core系列,还有服务器的Xeon至强和Itanium安腾。Intel一直保持在每一代新的处理器架构中优化硬件虚拟化的性能和增加新的虚拟化技术。现在市面上,从桌面的Core i3/5/7,到服务器端的E3/5/7/9,几乎全部都支持Intel VT技术。可以说, 在不远的将来, Intel VT很可能会成为所有Intel处理器的标准配置。当然AMD的CPU也都支持虚拟化技术。
总结
硬件辅助虚拟化貌似比BT技术更好,如果BT技术能够让虚拟机性能达到物理机80%的性能的话,那么硬件辅助虚拟化(HVM)就能够让虚拟机性能达到物理机85%左右。当然这中间的转换还是需要的,只不过是由硬件直接完成了,仅此而已。
二、全虚拟化和半虚拟化
Full-virtualization(全虚拟化)
全虚拟化为客户机提供了完整的虚拟X86平台, 包括处理器、 内存和外设, 支持运行任何理论上可在真实物理平台上运行的操作系统, 为虚拟机的配置提供了最大程度的灵活性。不需要对客户机操作系统做任何修改即可正常运行任何非虚拟化环境中已存在基于X86平台的操作系统和软件,这也是全虚拟化无可比拟的优势。
在全虚拟化情况下,虚拟机并不知道自己运行在虚拟化环境下,是无感知的,安装使用时跟在物理机上没有什么区别。但是这种完全虚拟化中间需要软件做支撑的,需要软件去模拟提供所有的硬件资源,至少是这个CPU的特权指令需要用软件去模拟的,因为你要让各Guest并不知道自己运行在虚拟环境中,那么你就必须要提供一个带有特权指令的CPU。
在虚拟化环境中,通常虚拟跟模拟是两个概念,VMWare的动态二进制翻译技术(BT)是虚拟的而QEMU软件技术是模拟的。最大的区别在于,模拟通过软件实现时需要模拟CPU ring 0-3,也就是需要转换CPU ring 0-3所有的指令,而虚拟只需要转换CPU ring 0特权指令即可。
当然不管上面说到的BT技术还是QEMU还是硬件辅助虚拟化技术都属于完全虚拟化技术,都是需要指令转换的,都是需要复杂的步骤才能完成的,如果我们能够精简这其中的步骤那么虚拟机的性能一定会有提升的。那么怎么精简呢?这就是下面说的半虚拟化技术。另外,在全虚拟化模式下:
CPU如果不支持硬件虚拟化技术:那么所有指令都是通过VMM虚拟的,通过VMM内的BT动态翻译技术把虚拟机要运行的特权指令转换为物理指令集,然后到CPU上运行。
CPU如果支持硬件虚拟化技术:VMM运行ring -1,而GuestOS运行在ring 0。
Para-virtualization(半虚拟化)
软件虚拟化可以在缺乏硬件虚拟化支持的平台上完全通过VMM软件来实现对各个虚拟机的监控,以保证它们之间彼此独立和隔离。 但是付出的代价是软件复杂度的增加,和性能上的损失。减轻这种负担的一种方法就是,改动客户操作系统,使它知道自己运行在虚拟环境下,能够与虚拟机监控机协同工作。这种方法就叫半虚拟化(para-virtualization)。虚拟机内核明确知道自己是运行在虚拟化之上的,对于硬件资源的使用不再需要BT而是自己向VMM申请使用,如对于内存或CPU的使用是直接向VMM申请使用,直接调用而非翻译。就算对于I/O设备的使用它也可以通过Hyper Call(Hypervisor提供的系统调用)直接可以跟硬件打交道,减少了中间的翻译步骤自然性能就好了,据说这种半虚拟化方式能够让虚拟化达到物理机90%的性能。本质上,半虚拟化弱化了对虚拟机特殊指令的被动截获要求,将其转化成客户机操作系统的主动通知。但是,半虚拟化需要修改客户机操作系统的源代码来实现主动通知。
Xen是开源准虚拟化技术的一个例子,操作系统作为虚拟服务器在Xen Hypervisor上运行之前,它必须在内核层面进行某些改变。因此,Xen适用于BSD、Linux、Solaris及其他开源操作系统,但不适合对像Windows这些专有的操作系统进行虚拟化处理,因为它们不
公开源代码,所以无法修改其内核。
总结
由于硬件辅助虚拟化的出现,使得完全虚拟化在性能上也得到了提升。并且相比半虚拟化而言,完全虚拟化使用上更加简化,虚拟过程对于Guest而言是透明的。所以完全虚拟化更加符合市场需求,比如后面说的KVM虚拟机。
内存虚拟化技术实现
说完虚拟化技术中最重要的CPU相关技术外,下面再来说说计算机五大部件中的第二大部件存储器,内存虚拟化技术。
首先我们知道内存本身就类似于虚拟化技术,其通过虚拟地址对外提供服务,所有的进程都以为自己可以使用所有的物理内存。如下图提供了在非虚拟化中和虚拟化中寻址方式。
")
No Virtualation
在非虚拟化中,系统把物理地址通过虚拟地址的方式(一个个页框)提供出去给进程使用,每个进程都以为自己可以使用所有的物理内存。本来在CPU上有个称为MMU(memory management unit)的东西,任何时候当某个进行想要访问数据自己的线性地址中的某段数据的时候,就是虚拟地址。这个进程就会传给CPU一个地址,并需要读取数据,但是CPU知道这个地址是无法真正访问到数据的,于是CPU要通过MMU将这段地址转换为对应物理地址的访问,从而这段数据就能访问到了。一般进程所得到的内存地址空间是一个连续的虚拟地址空间,而在真正的物理内存存储时一般都不会是连续的地址空间。
In Virtualation
为了实现内存虚拟化,让客户机使用一个隔离的、从零开始且具有连续的内存空间,像KVM虚拟机引入一层新的地址空间,即客户机物理地址空间 (Guest Physical Address, GPA),这个地址空间并不是真正的物理地址空间,它只是宿主机虚拟地址空间在客户机地址空间的一个映射。对客户机来说,客户机物理地址空间都是从零开始的连续地址空间,但对于宿主机来说,客户机的物理地址空间并不一定是连续的,客户机物理地址空间有可能映射在若干个不连续的宿主机地址区间。
从上图我们看出,在虚拟化环境中,由于虚拟机物理地址不能直接用于宿主机物理MMU进行寻址,所以需要把虚拟机物理地址转换成宿主机虚拟地址 (Host Virtual Address, HVA)。运行在硬件之上的Hypervisor首先会对物理内存进行虚拟地址 (Host Virtual Address, HVA)转换,然后还需要对转换后的虚拟地址内存空间进行再次虚拟,然后输出给上层虚拟机使用,而在虚拟机中同样又要进行GVA转换到GPA操作。显然通过这种映射方式,虚拟机的每次内存访问都需要Hypervisor介入,并由软件进行多次地址转换,其效率是非常低的。
因此,为了提高GVA到HPA转换的效率,目前有两种实现方式来进行客户机虚拟地址到宿主机物理地址之间的直接转换。其一是基于纯软件的实现方式,也即通过影子页表(Shadow Page Table)来实现客户虚拟地址到宿主机物理地址之间的直接转换(KVM虚拟机是支持的)。其二是基于硬件辅助MMU对虚拟化的支持,来实现两者之间的转换。
其中Shadow Page Table(影子页表),其实现非常复杂,因为每一个虚拟机都需要有一个Shadow Page Table。并且这种情况会出现一种非常恶劣的结果,那就是TLB(Translation Lookaside Buffer,传输后备缓冲器)很难命中,尤其是由多个虚拟主机时,因为TLB中缓存的是GVA到GPA的转换关系,所以每一次虚拟主机切换都需要清空TLB,不然主机之间就会发生数据读取错误(因为各主机间都是GVA到GPA)。传输后备缓冲器是一个内存管理单元用于改进虚拟地址到物理地址转换后结果的缓存,而这种问题也会导致虚拟机性能低下。
此外,Intel的EPT(Extent Page Table) 技术和AMD的NPT(Nest Page Table) 技术都对内存虚拟化提供了硬件支持。这两种技术原理类似,都是在硬件层面上实现客户机虚拟地址到宿主机物理地址之间的转换。称为Virtualation MMU。当有了这种MMU虚拟化技术后,对于虚拟机进程来说还是同样把GVA通过内部MMU转换为GPA,并不需要改变什么,保留了完全虚拟化的好处。但是同时会自动把GVA通过Virtualation MMU技术转换为真正的物理地址(HPA)。很明显减少了由GPA到HPA的过程,提升虚拟机性能。
并且CPU厂商还提供了TLB硬件虚拟化技术,以前的TLB只是标记GVA到GPA的对应关系,就这两个字段,现在被扩充为了三个字段,增加了一个主机字段,并且由GVA到GPA以及对应变成了GVA到HPA的对应关系。明确说明这是哪个虚拟机它的GVA到HPA的映射结果。
总结
由此看出内存虚拟化,如果没有硬件做支撑,那么只能使用Shadow Page Table(影子页表),也就意味着TLB需要不断地进行清空。而有了内存虚拟机技术后,虚拟机的性能在某种程度上也得到了大大地提升。
I/O虚拟化技术实现
从处理器的角度看,外设是通过一组I/O资源(端口I/O或者是MMIO)来进行访问的,所以设备的相关虚拟化被称为I/O虚拟化,如:
1)外存设备:硬盘、光盘、U盘。
2)网络设备:网卡。
3)显示设备:VGA(显卡)。
4)键盘鼠标:PS/2、USB。
还有一些如串口设备、COM口等等设备统称IO设备,所谓IO虚拟化就是提供这些设备的支持,其思想就是VMM截获客户操作系统对设备的访问请求,然后通过软件的方式来模拟真实设备的效果。基于设备类型的多样化,I/O虚拟化的方式和特点纷繁复杂,我们挑一些常用IO设备说一说。
但一般IO虚拟化的方式有以下三种,如下图:
")
第一种:模拟I/O设备
完全使用软件来模拟,这是最简单但性能最低的方式,对于IO设备来说模拟和完全虚拟化没有太大意义上的区别。VMM给Guest OS模拟出一个IO设备以及设备驱动,Guest OS要想使用IO设备需要调内核然后通过驱动访问到VMM模拟的IO设备,然后到达VMM模拟设备区域。VMM模拟了这么多设备以及VMM之上运行了那么多主机,所以VMM也提供了一个I/O Stack(多个队列)用来调度这些IO设备请求到真正的物理IO设备之上。经过多个步骤才完成一次请求。
举例:Qemu、VMware Workstation
第二种:半虚拟化
半虚拟化比模拟性能要高,其通过系统调用直接使用I/O设备,跟CPU半虚拟化差不多,虚拟化明确知道自己使用的IO设备是虚拟出来的而非模拟。VMM给Guest OS提供了特定的驱动程序,在半虚拟化IO中我们也称为“前端IO驱动”;跟模拟I/O设备工作模式不同的是,Guest OS自己本身的IO设备不需要处理IO请求了,当Guest OS有IO请求时通过自身驱动直接发给VMM进行处理,而在VMM这部分的设备处理我们称之为“后端IO驱动”。
举例:Xen、virtio
第三种:I/O透传技术
I/O透传技术(I/O through)比模拟和半虚拟化性能都好,几乎进阶于硬件设备,Guest OS直接使用物理I/O设备,操作起来比较麻烦。其思想就是提供多个物理I/O设备,如硬盘提供多块,网卡提供多个,然后规划好宿主机运行Guest OS的数量,通过协调VMM来达到每个Guest OS对应一个物理设备。另外,要想使用I/O透传技术,不光提供多个I/O设备还需要主板上的I/O桥提供支持透传功能才可以,一般Intel提供的这种技术叫VT-d,是一种基于北桥芯片的硬件辅助虚拟化技术,主要功能是由来提高I/O灵活性、可靠性和性能的。
为什么I/O透传还需要主板支持呢?每个虚拟机直接使用一个网卡不就可以了吗?主要是因为在我们传统的X86服务器架构上,所有的IO设备通常有一个共享或集中式的DMA(直接内存访问),DMA是一种加速IO设备访问的方式。由于是集中式的,所以在VMM上管理多块网卡时其实使用的还是同一个DMA,如果让第一个Guest OS直接使用了第一块网卡,第二个Guest OS直接使用第二块网卡,但使用的DMA还是同一个,而DMA是无法区分哪个Guest OS使用的是哪块网卡,这就变的麻烦了。而像Intel的VT-d就是用来处理这些问题的,以及处理各主机中断。
举例:Intel VT-d
对应具体设备是如何实现?
1)硬盘如何虚拟化?
虚拟化技术中,CPU可以按时间切割,内存可以按空间切割,那么磁盘设备呢?也可以按照空间来切割,把硬盘划分成一个一个的区域。但是好像没有这么用的,一般磁盘虚拟化的方式就是通过模拟的技术来实现。
2)网卡如何虚拟化?
网卡的虚拟化方式一般使用模拟、半虚拟化、IO透传技术都行,其实现方式根据VMM的不同有所不同,一般的VMM都会提供所有的方式。
3)显卡如何虚拟化?
显卡虚拟化通常使用的方式叫frame buffer(帧缓存机制),通过frame buffer给每个虚拟机一个独立的窗口来实现。当然其实对于显示设备的虚拟化是比较麻烦的,所以通常在虚拟化环境中我们的显示设备性能都不会很好的,当然安装个Windows显示还是没有问题的,但不适用图形处理类的服务。
4)键盘鼠标如何虚拟化?
我们在虚拟机中使用键盘鼠标通常都是通过模拟的方式实现的,通过焦点捕获将模拟的设备跟当前设备建立关联关系,比如你使用Vmware workstation时把鼠标点进哪个虚拟机后,相当于被此虚拟机捕获了,所有的操作都是针对此虚拟机了。
总结
简单描述了CPU虚拟化、内存虚拟化、IO虚拟化的实现方式。其一,我们大概知道了如何选择虚拟化主机性能会最大化,CPU支持硬件辅助虚拟化技术,如Intel的VT;内存支持硬件辅助虚拟化技术,如Virtualization mmu和TLB;IO支持硬件辅助虚拟化技术,如Intel的VT-d。当然光有硬件的支持还不是太够,在使用虚拟化时要能够充分利用到这些硬件才行。
虚拟化的运行模式
Type-I:直接运行在操作系统之上的虚拟化,模式如下图:
")
如:Vmware workstations、Kvm等。
Type-II:直接运行在硬件之上的(提供各种硬件驱动),模式如下图:
")
如:Vmware EXSI、Xen等。
但是Xen有点特别,虽然也是直接安装在硬件之上,提供Hypervisor,但是只负责CPU、内存、中断,不提供I/O驱动,需要额外安装一个虚拟机再安装一个Linux系统用来管理I/O设备,如下图:
")
Type-III:其他类型
当然,除了上面提到的基于操作系统或直接基于硬件的虚拟化外,还有如下常见的类型。
容器虚拟化
基于内核的虚拟化,所有的虚拟机都是一个独立的容器,但共同运行硬件之上,使用着同一个内核。优点就是速度快,部署容易,缺点就是相互间的资源相互隔离比较麻烦,但现在市场也都有了相对成熟的解决方案。如,如今大火的Docker,网上都有人说Docker具有取代虚拟化的势头。
模拟器虚拟化
通过模拟器模拟所有的硬件,如QEMU,KVM就是使用QEMU。
库虚拟化
通过在操作系统之上模拟出不同系统的库,如Linux上运行Wine就可以支持Windows上的软件运行,Windows上运行Cywin就可以支持Linux上的软件运行。因为现在操作系统都是遵循POSIX标准,所以各自提供的库接口都是同一个标准,只需要在对应的平台上运行一个可以提供对方库的软件,然后在此软件之上运行针对对方系统编译好的软件即可。为什么要运行针对对方平台编译好的软件,因为虽然库统一了,但是各自的ABI(应用二进制接口)接口还是不同的。
X86平台实现虚拟化技术的挑战?
首先我们知道X86处理器有4个特权级别,Ring 0~Ring 3,只有运行在Ring 0 ~ 2级时,处理器才可以访问特权资源或执行特权指令,运行在Ring 0级时,处理器可以运行所有的特权指令。X86平台上的操作系统一般只使用Ring 0和Ring 3这两个级别,其中,操作系统内核运行在Ring 0级,也被称为内核空间指令,用户进程运行在Ring 3级,也被称为用户空间指令。
特权级压缩(ring compression)
为了满足上面所述的需求,VMM自身必须运行在Ring 0级,同时为了避免Guest OS控制系统资源,Guest OS不得不降低自身的运行级别而运行于Ring 3(Ring 1、2 不使用)。
此外,VMM使用分页或段限制的方式保护物理内存的访问,但是64位模式下段限制不起作用,而分页又不区分Ring 0,1,2。为了统一和简化VMM的设计,Guest OS只能和用户进程一样运行在Ring 3。VMM必须监视Guest OS对GDT、IDT等特权资源的设置,防止Guest OS运行在Ring 0级,同时又要保护降级后的Guest OS不受Guest进程的主动攻击或无意破坏。
特权级别名(Ring Alias)
设计上的原因,操作系统假设自己运行于ring 0,然而虚拟化环境中的Guest OS实际上运行于Ring 1或Ring 3,由此,VMM必须保证各Guest OS不能得知其正运行于虚拟机中这一事实,以免其打破前面的“等价执行”标准。例如,x86处理器的特权级别存放在CS代码段寄存器内,Guest OS却可以使用非特权PUSH指令将CS寄存器压栈,然后POP出来检查该值;又如,Guest OS在低特权级别时读取特权寄存器GDT、LDT、IDT和TR时并不发生异常。这些行为都不同于Guest OS的正常期望。
地址空间压缩(Address Space Compression)
地址空间压缩是指VMM必须在Guest OS的地址空间中保留一段供自己使用,这是x86虚拟化技术面临的另一个挑战。VMM可以完全运行于自有的地址空间,也可以部分地运行于Guest OS的地址空间。前一种方式,需在VMM模式与Guest OS模式之间切换,这会带来较大的开销;此外,尽管运行于自己的地址空间,VMM仍需要在Guest OS的地址空间保留出一部分来保存控制结构,如IDT和GDT。无论是哪一种方式,VMM必须保证自己用到地址空间不会受到Guest OS的访问或修改。
非特权敏感指令
x86使用的敏感指令并不完全隶属于特权指令集,VMM将无法正确捕获此类指令并作出处理。例如,非特权指令SMSW在寄存器中存储的机器状态就能够被Guest OS所读取,这违反了经典虚拟化理论的要求。
静默特权失败(Silent Privilege Failures)
x86的某些特权指令在失败时并不返回错误,因此,其错误将无法被VMM捕获,这将导致其违反经典虚拟化信条中的“等价执行”法则。
中断虚拟化(Interrupt Virtualization)
虚拟化环境中,屏蔽中断及非屏蔽中断的管理都应该由VMM进行;然而,GuestOS对特权资源的每次访问都会触发处理器异常,这必然会频繁屏蔽或启用中断,如果这些请求均由VMM处理,势必会极大影响整体系统性能。