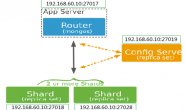
一、分片请求查询机制
当对一个集合进行分片之后,必然面临的一个问题就是如果查询数据了。大概会通过以下几种方式进行数据的查询。
方式一:简单通过路由查询(Routed Request)
")
当一个查询请求发送到mongos之后,mongos会根据内部的一些机制定位到某一个shard上面,然后shard将查询结果返回给mongos。
方式二:分散聚合查询(scatter gather request)
")
当一个查询请求发送到mongos之后,mongos会将此查询分散到多个shard节点进行查询。然后shard成员节点返回对应的结果由mongos进行结合将最终的结果返回给用户。
方式三:分布式排序查询机制(distributed merge sort request)
")
当一个排序查询请求发送到mongos之后,mongos会将此查询分散到多个shard节点进行查询。然后shard成员节点返回对应的结果(此结果是在shard内部排好序的)由mongos进行结合将最终的结果返回给用户。
二、如非必要,慎用分片
分片会导致系统复杂程序大增,所以,如果没有必要,请不要使用分片。下面我们先讲两种不用分片就能让系统具有扩展性的方法。
1. 读写分离
大多数应用场景都是读多写少的场景。所以在这种情况下,可以用一个简单的方法来分担负载,就是把数据同步到多台机器上。这时候写请求还是由master机器处理,而读请求则可以分担给那些同步到数据的机器了。而同步数据的操作,通常是不会对master带来多大的压力的。
如果你已经使用了主从配置,将数据同步到多台机器以提供高可靠性了,那么你的slave机器应该能够为master分担不少压力了。对有些实时性要求不是非常高的查询请求,比如一些统计操作,你完全可以放到slave上来执行。通常来说,你的应用对实时性要求越低,你的slave机器就能承担越多的任务。
2. 使用缓存
将一些经常访问的数据放到缓存层中,通常会带来很好的效果。Memcached主要的作用就是将数据层的数据进行分布式的缓存。Memcached通过客户端的算法(译者: 常见的一致性hash算法)来实现横向扩展,这样当你想增大你缓存池的大小时,只需要添加一台新的缓存机器即可。
由于Memcached仅仅是一个缓存存储,它并不具备一些持久存储的复杂特性。当你在考虑使用复杂的扩展方案时,希望你先考虑一下使用缓存来解决你的负载问题。注意,缓存并不是临时的处理方案:Facebook就部署了总容量达到几十TB的Memcahced内存池。
通过读写分离和构建有效的缓存层,通常可以大大分担系统的读负载,但是当你的写请求越来越频繁的时候,你的master机器还是会承受越来越大的压力。对于这种情况,我们可能就要用到下面说到的数据分片技术了。