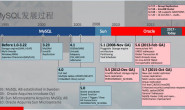
MySQL5.6 features
This is the MySQL™ Reference Manual. It documents MySQL 5.6 through 5.6.28
http://dev.mysql.com/doc/refman/5.6/en/
http://dev.mysql.com/doc/refman/5.6/en/mysql-nutshell.html
添加的新特性(Added Features)
安全提高(security)
1)提供保存加密认证信息的方法,使用.mylogin.cnf文件。使用mysql_config_editor可以创建此文件。这个文件可以进行连接数据库的访问授权。mysql_config_editor会进行加密而不是明文存储。客户端只会在内存中进行解密。这样密码以非明文方式存储,不会在命令行或者环境变量中暴露。
2)mysql.user表现在增加password_expired列,默认值是’N’,使用新的ALTER USER命令可以设置为’Y’。当密码过期后,使用此账号的后续连接都会报错,只到用户使用SET PASSWORD命令创建一个新密码。
3)现在提供密码安全策略,使用明文指定密码时,密码会被当前的密码策略检查,如果太弱会被拒绝(返回ER_NOT_VALID_PASSWORD 错误)。会影响CREATE USER, GRANT, 和SET PASSWORD命令。密码作为参数被password(),old_password()引用时也会被检查。
优化器提升(Optimization)
1)查询优化器对于以下查询(子查询)更有效率SELECT … FROM single_table … ORDER BYnon_index_column[DESC] LIMIT [M,]N;
此类在大结果集中显示几行的查询在网站中很常见。如:SELECT col1, … FROM t1 … ORDER BY name LIMIT 10; SELECT col1, … FROM t1 … ORDER BY RAND() LIMIT 15。排序缓存由 sort_buffer_size.指定。如果N行被排序的元素足够小可以被入排序缓存(M+N行如果M被指定),可以避免使用合并文件,整个查询可以都放入内存中。见Section 8.2.1.3, “Optimizing LIMIT Queries”。
2)优化器使用MRR,使用非聚集索引进行索引扫描时,如果表很大没有缓存,会导致大量的随机磁盘访问。使用MRR优化,优化器会先对扫描索引,然后收集每行的主键并对主键排序,此时就可以用主键顺序访问基表。这样就用顺序访问代替了随机磁盘访问。
3)优化器使用ICP,没有ICP,引擘使用索引定位行,并返回给服务层,使用where丢弃不符合条件记录。使用ICP后,如果索引中只有部分能被where条件利用,MySQL将where条件压到引擘层。引擘层使用索引项进行评估,只有满足条件的会被读取。ICP可以减少引擘层对基表的访问,同时减少了服务层对引擘层的访问。
4)EXPLAIN命令现在可以用在DELETE, INSERT, REPLACE,UPDATE语句上。以前,只能用在查询语句上。另外,现在支持json格式输出。
5)优化器对于from子句的子查询更有效率,查询执行中会物化子查询以提高性能,另外,优化器还可能对派生表创建索引来加速行检索。
6)优化器使用semi-join和物化来优化子查询。
7)对关联表查询或者使用join buffer的查询,新算法BKA被使用。BKA支持inner join,outer join,semi-join,包手nested outer joins 和 nested semi-joins。好处是提高了表扫描的性能。
8)优化器有追踪功能,对于开发者很有用。
数据类型(Data types)
1)TIME, DATETIME, 和 TIMESTAMP 支持更小时的时间粒度,精确到微秒(6位)。
2)以前每个表最多只有一个TIMESTAMP 列可以用当前时间初始化和更新。这个限制没有了。所有TIMESTAMP列都可以设置这2个属性。另外,DATETIME 也支持这些属性了。
3)YEAR(2)类型被抛弃,现存的表中的year(2)列会和以前一样处理,但新建或者修改表结构时会转化为YEAR(4)
InnoDB的增强(The InnoDB storage engine)
1)MySQL 5.6 完全集成 InnoDB 作为默认的存储引擎。同时 5.6 版本在使用 InnoDB 上的很多细节做了改进。
2)InnoDB现在可以限制大量表打开的时候内存占用过多的问题(比如这里提到的)(第三方已有补丁)。
3)Innodb redo log大小从最大4GB提高到512GB,通过参数 innodb_log_file_size 配置。
4)Innodb使用了一种新的,更快的算法来检测deadlocks. 所有死锁信息都可以被记录到错误日志。方便分析。
5)Online DDL,几种ALTER TABLE操作不再拷备表,不会阻塞insert,update,delete或者全部写入操作。仍然有一些Alter操作需要重建表,比如增加/删除列,增加/删除主键,改变数据类型等。这也就是所谓的online DDL。(之前版本中DDL操作需要全部加锁重建表)。
6)Innodb强化了几种内部性能,包括拆分kernel mutex来减少竞争,将刷新操作移出主线程,允许使用多个清理线程,以及减少了大内存系统中的buffer_pool竞争。
7)可以通过NoSQL API开发应用访问InnnoDB表。它使用流行的memcached守护进程来响应对于key-value对的Add,Set和GET请求。这样避免了解析和构建query execution plan的成本。你可以使用NoSQL API或者SQL来访问同一份数据。比如:你可以通过NoSQL API快速访问和查询表数据,使用SQL来进行复杂查询以及兼容已有的应用,大大提升了数据访问的性能。
8)为了避免大buffer_pool的实例重启服务时过长的warmup 时间,你可以在重启后立即加载缓存页面。MySQL可以在关闭时导出完全数据文件,检阅此文件找出重启时需要加载的pages。你可以在任何手工导入导出buffer_pool,比如在性能测试时或者在执行复杂的OLAP查询后。
分区的改进(partition)
1)最大分区数量提高到8192,这包括所有的分区和子分区。使用ALTER TABLE … EXCHANGE PARTITION 可以在未分区表和分区表和子分区表之间交换分区。这可以用来导出导入分区。
2)支持显式分区数据查询,例如:
SELECT * FROM employees PARTITION (p0, p2);
DELETE FROM employees PARTITION (p0, p1);
UPDATE employees PARTITION (p0) SET store_id = 2 WHERE fname = ‘Jill’;
SELECT e.id, s.city FROM employees AS e JOIN stores PARTITION (p1) AS s …;
复制和日志(replication)
1)支持延时复制,MySQL现在支持延迟复制,默认是0秒。使用CHANGE MASTER TO参数 MASTER_DELAY 来设置延迟。可以让slave跟master之间控制一个时间间隔,方便特殊情况下的数据恢复。(以前是使用第三方工具可以做到)
2)行级复制功能加强,可以降低磁盘、内存、网络等资源开销(只记录能确定行记录的字段即可)。
3)现在支持多线程复制。如果开启,sql线程作为协调者协调多个工作线程,数量取决于slave_parallel_workers 。现在多线程复制以单库为基础,特定库的更新的相对顺序和主库一样。不过,没有必要协调不同库之间的事务。事务可以被分布到每个库,意味着一个复制从库的工作线程可以顺序执行事务而不必等待其它库的更新完成。
4)支持以全局统一事务ID(GTID)为基础的复制。当在主库上提交事务或者被从库应用时,可以定位和追踪每一个事务。GTID复制是全部以事务为基础,使得检查主从一致性变得非常简单。如果所有主库上提交的事务也同样提交到从库上,一致性就得到了保证。
5)支持启用GTID,对运维人员来说应该是一件令人高兴的事情,在配置主从复制,传统的方式里,你需要找到binlog和POS点,然后change master to指向,而不是很有经验的运维,往往会将其找错,造成主从同步复制报错,在mysql5.6里,如果使用了GTIDs,启动一个新的复制从库或切换到一个新的主库,就不必依赖log文件或者pos位。需要知道master的IP、端口,账号密码即可,因为同步复制是自动的,mysql通过内部机制GTID自动找点同步。
6)binlog的读写现在是崩溃安全的,因为只有完整的事件(或者事务)才会被记录和读取。默认会记录事件的大小以及事件本身,使用大小来验证事件被正确记录。你也可以使用参数binlog_checksum设置使用crc32记录事件的校验值。使用参数 master_verify_checksum可以让服务读取校验值。slave-sql-verify-checksum 参数使从库读relay日志的时候读取校验值。
MySQL支持在表中保存主库连接信息了。使用参数–master-info-repository 和 –relay-log-info-repository 来设置。设置 –master-info-repository 为表,会记录连接信息到slave_master_info 表。设置–relay-log-info-repository 为表,会记录relay log信息到slave_relay_log_info表。这几个表都是自动建立在mysql系统库。
增强Performance Schema数据库(Mysql performance schema)
1)记录表的输入与输出,操作包括行级访问表和临时表,如insert,upate,delete.
2)表的事件过滤,以库或者表名为基础。
3)线程的事件过滤,更多关于线程的信息被搜集
4)表和索引I/O以及表锁的统计表。
5)记录命令以及命令的阶段。
移除的特性(Removed Features)
以下被参数移除,同时会显示新的参数。
移除–log,换为–general_log 指定是否开启,–general_log_file=file_name 指定文件名。
移除–log-slow-queries和 log_slow_queries,用–slow_query_log 开启慢查询日志,用–slow_query_log_file=file_name 指定文件名。
移除–one-thread ,使用–thread_handling=no-threads 替换。
移除–safe-mode
移除–skip-thread-priority
移除–table-cache,改为table_open_cache
移除–init-rpl-role 和 –rpl-recovery-rank选项和rpl_recovery_rank 系统参数,以及Rpl_status状态值。
移除engine_condition_pushdown,使用engine_condition_pushdown标识optimizer_switch 参数。
移除have_csv, have_innodb, have_ndbcluster, 和 have_partitioning,使用show engines替换。
移除sql_big_tables,使用big_tables。
移除sql_low_priority_updates ,使用low_priority_updates 。
移除 sql_max_join_size,使用 max_join_size 。
移除max_long_data_size,使用max_long_data_size。
移除 FLUSH MASTER 和 FLUSH SLAVE命令,使用RESET MASTER 和 RESET SLAVE 替换。
移除SLAVE START 和 SLAVE STOP命令,使用START SLAVE 和 STOP SLAVE替换。
移除SHOW AUTHORS 和 SHOW CONTRIBUTORS命令。
移除set命令的OPTION and ONE_SHOT修改器。
不允许在存储过程中或者函数参数中或者存储程序本地变量中使用default来指定(如:SET var_name = DEFAULT命令),但可以在指定系统变量时使用default。