做过 MySQL 主从复制的同学都知道,主从复制能够有效工作的一些基本原则,如下:
- master 必须开启 binlog,这是主从复制能够工作的基本要求,slave 需要同步 master 的 binlog 进行回放来同步数据。
- master 和 slave 实例都需要设置 server_id,且不能相同,否则复制会报错;同一个复制集群中必须保证 server_id 唯一。
- 每个 master 可以有多个 slave,从 MySQL 5.7 开始支持多源复制,允许单个 slave 有多个 master。
- slave 开启 binlog,并设置 log_slave_updates 参数,其可以作为其他它 slave 的 master,从而扩散 master 的更新,这种复制方式被称为联级复制。
这几个基本原则都比较容易理解,对于 master 和 slave 实例都需要设置 server_id,且不能相同,和同一个复制集群(指各种复制拓扑)必须保证 server_id 唯一。这点就有问题可以思考了,大概总结如下。
1. master 与 slave 的 server_id 不能相同,主要是 slave 要依靠 server_id 来决定是否执行事件
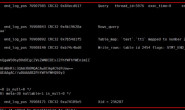
在双主复制结构中,master 发生数据更新,会在 binlog event 的 header 中存储 server_id,然后发送到 slave。
然后 slave 的 io 线程通过读取到 event 拿到 server_id,判断此 server_id 与自己的 server_id 是否相同,相同则丢弃,否则记录 event 到 relay log。然后通过 sql 线程回放 event 并记录到 binlog 中,这里记录的 event 是 master 的 binlog event,也就是说其 server_id 是 Master 的,而不是 Slave 的。
slave 会将 binlog event 通过 dump 线程又发送给 master,因此最初 master 上执行的 binlog event 又传了回来,同样 master 通过读取 event header 中存储的 server_id,判断与自己的 server_id 是否一致,相同则丢弃,否则记录 event 到 relay log。
在这个过程中,如果 master 记录的 binlog event 的 server_id 与 master&slave 的 server_id 都不相同,则该 binlog event 则在 master&slave 中无限循环执行,也就是通常所说的复制风暴。最简单产生这种问题的架构 M -> (MS <-> MS)。
2. 当 Master 有多个 Slave 时,那么如何来区分这些 Slave 呢?
MySQL 5.6 版本之前就需要用到 server_id。
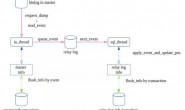
我们首先看看一个 slave 向 master 请求二进制时会发生什么?首先 slave 会向 master 发送一个 COM_BINLOG_DUMP 命令,会带上自己的 server_id 和 binlog filename & position 信息。然后 master 会调用 kill_zombie_dump_threads 函数,这个函数会遍历 MySQL 中的所有线程,如果遍历到一个线程是 dump 线程并且线程的 server_id 是等于 slave 的 server_id,则跳出遍历循环,并对 kill 掉这个线程。
但 MySQL 5.6 版本时,因为有了 uuid 的概念,所以 kill_zombie_dump_threads 函数逻辑也变动了,会先调用 get_slave_uuid 函数获取 slave uuid,然后同样会遍历 MySQL 中的所有线程,但如果找到 dump 线程时,首先看一下这个线程有没有 uuid 字段(兼容 <MySQL 5.6 版本),如果有 uuid 字段并且 slave 的 uuid 不为空,则进行比较,否则用 server_id 进行比较。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 |
void kill_zombie_dump_threads(THD *thd) { String slave_uuid; get_slave_uuid(thd, &slave_uuid); if (slave_uuid.length() == 0 && thd->server_id == 0) return; Find_zombie_dump_thread find_zombie_dump_thread(slave_uuid); THD *tmp= Global_THD_manager::get_instance()-> find_thd(&find_zombie_dump_thread); if (tmp) { /* 这里我们没有调用 kill_one_thread(),因为它将会很慢,它将会再次遍历列表,而我们只是要自己杀死线程。 */ if (log_warnings > 1) { if (slave_uuid.length()) { sql_print_information("While initializing dump thread for slave with " "UUID <%s>, found a zombie dump thread with the " "same UUID. Master is killing the zombie dump " "thread(%u).", slave_uuid.c_ptr(), tmp->thread_id()); } else { sql_print_information("While initializing dump thread for slave with " "server_id <%u>, found a zombie dump thread with the " "same server_id. Master is killing the zombie dump " "thread(%u).", thd->server_id, tmp->thread_id()); } } tmp->duplicate_slave_id= true; tmp->awake(THD::KILL_QUERY); mysql_mutex_unlock(&tmp->LOCK_thd_data); } } |
事实上,如果 slave 停止了,而 Binlog_dump 线程正在等待(mysql_cond_wait)binlog 更新,那么它将一直存在,直到有查询被写入 binlog。如果 master 是空闲的,那么这可能会持续很长时间,如果 slave 重新连接,就可能会有 2 个 Binlog_dump 线程。为了避免这种情况,当 slave 重新连接并发送 COM_BINLOG_DUMP,master 会杀死任何带有 slave 的 uuid/server_id 的现有线程(如果这个 id 不是零的话;对于真正的 slave 来说,它将是真的,但对于 mysqlbinlog 来说,当它发送 COM_BINLOG_DUMP 以获得远程 binlog 时,它是假的)。
结论就是在一个复制集群中,必须保证 server_id 都唯一,避免可能会有一些不可预知的错误。
<参考>
MySQL多个Slave同一server_id的冲突原因分析