现在数据库标配基本都是SSD了,在使用SSD之前,对SSD进行了充分的测试,这其中当然包括最为关键的性能测试部分。下面就跟大家分享一下在SSD性能测试过程中遇到的一个问题和解决问题的思路。
我们的性能测试使用的测试工具是Sysbench,测试场景主要包括5类:全内存非事务更新(nontrx)、全内存事务更新(complex)、非全内存查询(select)、非全内存非事务更新(nontrx)、非全内存的事务更新(complex)。在非全内存的事务更新测试中,我们发现了一个奇怪的现象,如下图所示:

MySQL实例的TPS会出现周期性的降到0的现象,要解释这个想象,我们首先就要先分析一下MySQL事务提交的流程。
MySQL一般使用Innodb作为底层存储引擎,而Innodb是一种基于磁盘存储的系统,即所有的数据最终都需要保存在磁盘上。为了提高效率,MySQL使用了内存缓冲池的技术,对于每次用户的更新请求,如果用户需要更新的数据已经在缓冲池中,则直接更新内存的缓冲池;如果缓冲池未命中,Innodb会将要更新的数据页先从磁盘读入内存,然后进行更新,也就是说所有的更新都是在内存中完成的!
内存中被更新的数据页我们称之为脏页,脏页最终再通过异步的方式刷新到磁盘上。为了保证事务的ACID特性,所有对缓冲池中的数据的更新都需要记日志,称为重做日志(redo log)或者Innodb存储引擎日志。一旦MySQL崩溃,系统就可以根据redo log将原先未刷新到磁盘上的更新刷新到磁盘上,这样就保证了数据不会丢失。
但是内存能够容纳的脏页是有限的,同时由于redo log只有记录的更新刷新到磁盘,redo log才可以被覆盖重写,所以MySQL使用了检查点的技术,根据一定的策略将内存中的脏页刷出到磁盘上。

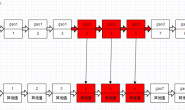
如图所示,经过上面4个步骤,用户的更新才会真正落到磁盘上。所谓检查点,本质上就是redo log的一个偏移量,该位置之前的日志所记录的更新一定已经刷新到磁盘上了,所以该位置之前的日志都是可以被覆盖重写的,这也意味着在MySQL崩溃恢复时,检查点之前的更新由于一定是已经刷新到磁盘上了,所以是不需要重做的,可以直接跳过。
所以整个日志空间可以描述为下面这个图。

为了保证未刷脏页的redo log不被覆盖,MySQL使用了下面的脏页刷新策略。若将已经写入到重做日志的LSN记为redo_lsn,将已经刷新回磁盘最新页的LSN记为checkpoint_lsn,则未刷新到磁盘的脏页的redo log可定义为:log cap = redo_lsn – checkpoint_lsn。
例如当log cap(指未刷新到磁盘脏页的日志大小)大于整个日志空间的75%时,系统会触发checkpoint,异步的将log cap部分的日志涉及的脏页刷到磁盘上,但是此时事务提交不会终止,也就是说还允许有redo log的继续写入。但是如果log cap继续增加,当超过整个日志空间的90%时,MySQL会停止事务的更新,此时redo log也会停止写入,必须等到刷足够的脏页时,才能允许事务再次提交。本质上说,如果事务提交的速度大于脏页刷盘的速度,最终都会触发上述日志保护的功能,即最终系统停止事务的更新,来保证日志记录的脏页能够刷新到磁盘上。
这就解释了我们上面看到的TPS出现周期性的降到0的情况,但是有一个疑问,为什么在机械盘上却很少看到上述的情况呢?这要从SSD IO特性讲起。普通的机械磁盘是依靠磁头移动来实现数据的定位的,所以其随机读写能力受限于磁盘的转速,相对于SSD有非常明显的差距,而顺序IO,普通机械磁盘相对于SSD,并没有太多的差距。那就有个疑问,日志本身是顺序IO,在SSD上和机械磁盘上写日志本身应该没有太大的差别,但是千万不要忘记,在写日志的时候,同时也在刷脏页,为了保证事务安全,一般我们会设置每次事务提交都会刷新log buffer到磁盘,而log buffer默认8M,本身是很小的IO,刷脏页是随机IO,刷脏页和写日志交错进行,磁盘的IO也不再顺序IO,而会变成随机IO,这样物理磁盘和SSD就会出现差别,SSD虽然会有写放大的因素,随机写相对随机读性能较差,但是相对于普通机械磁盘,还是有非常大的优势的,所以SSD就会出现日志的写入速度远远大于检查点的推进速度,但是在普通物理机械磁盘上,就不容易出现,因为刷脏页的随机IO会拖慢事务的提交速度,日志写入序号与检查点之间的差距增长不会那么快。这也就是为什么在SSD的场景下更容易出现MySQL TPS周期性波动的原因。
分析清楚了问题产生的原因,下一步我们来看看有什么办法来解决这个问题。首先,问题产生的原因归根到底就是脏页刷的太慢,事务提交的太快,日志空间不足以支撑他们之间速度的差距。事务提交的速度我们固然无法让其降低,但是我们可以从加快脏页的刷新来想想办法。Innodb在刷脏页的时候有一个关键特性就是会将脏页临近的脏页一并刷出,这样也可以将随机IO转化成顺序IO,当然,如果脏页被再次更新,就会存在重复刷新的问题,但是对于普通磁盘而言,这点开销是完全值得的。但是对于SSD,随机IO能力相对于顺序IO并没有非常大的差距,所以完全可以关闭刷新邻接脏页!这样一方面可以减少脏页刷新的数量,另一方面也可以避免脏页再次被更新后出现的重复刷新的问题。
在MySQL中一次刷新的脏页的数量有一个 innodb_io_capacity的参数进行控制, innodb_io_capacity越大,一次刷新的脏页的数量也就越大,在SSD的场景下,由于IO能力大大增强,所以 innodb_io_capacity需要调高,可以配置到2000以上,但是对于普通机械磁盘,由于其随机IO的IOPS最多也就是300,所以innodb_io_capacity开的过大,反而会造成磁盘IO不均匀。最后还需要再提一点,就是可以在SSD的场景下适当增大redo log的大小,当然这个不能从根本解决上述TPS 波动的问题,只是能够将两次TPS波动的距离拉长。经过上述优化测试,我们得到对于结果如下图所示:

红色是优化后的TPS曲线,蓝色是原先的TPS曲线,TPS周期性的降到0的问题消失啦!
总结一下:针对SSD可以选择关闭InnoDB刷新临接页特性,可以适当调大innodb_io_capacity值,另外可以参考:SSD下的 MySQL IO优化。
<转载>
http://backend.blog.163.com/blog/static/2022941262013102811320942
http://dimitrik.free.fr/blog/posts/mysql-80-innodb-checkpointing.html