背景介绍
本文涵盖了6个开源领导者:Hive、Impala、Spark SQL、Drill、HAWQ 以及Presto,还加上Calcite、Kylin、Phoenix、Tajo 和Trafodion。以及2个商业化选择Oracle Big Data SQL 和IBM Big SQL,IBM 尚未将后者更名为“Watson SQL”。
(有读者问:Druid 呢?我的回答是:检查后,我同意Druid 属于这一类别。)
使用SQL 引擎一词是有点随意的。例如Hive 不是一个引擎,它的框架使用MapReduce、TeZ 或者Spark 引擎去执行查询,而且它并不运行SQL,而是HiveQL,一种类似SQL 的语言,非常接近SQL。“SQL-in-Hadoop” 也不适用,虽然Hive 和Impala 主要使用Hadoop,但是Spark、Drill、HAWQ 和Presto 还可以和各种其他的数据存储系统配合使用。
不像关系型数据库,SQL 引擎独立于数据存储系统。相对而言,关系型数据库将查询引擎和存储绑定到一个单独的紧耦合系统中,这允许某些类型的优化。另一方面,拆分它们,提供了更大的灵活性,尽管存在潜在的性能损失。
下面的图1展示了主要的SQL 引擎的流行程度,数据由奥地利咨询公司Solid IT 维护的DB-Engines 提供。DB-Engines 每月为超过200个数据库系统计算流行得分。得分反应了搜索引擎的查询,在线讨论的提及,提供的工作,专业资历的提及,以及tweets。
Apache Hive:41.65(4月数据) -2.97(对比3月) -7.43(对比2016年)
Apache Impala:11.23 +0.86 +2.94
Apache SparkSQL:7.92 +0.60 +2.93
Apache Drill:2.93 -0.01 +1.09
Apache HAWQ:0.89 +0.06 +0.20
Presto:0.66 +0.12 +0.32
来源:DB-Engines,2017年4月 http://db-engines.com/en/ranking
虽然Impala、Spark SQL、Drill、Hawq 和Presto 一直在运行性能、并发量和吞吐量上击败Hive,但是Hive 仍然是最流行的(至少根据DB-Engines 的标准)。原因有3个:
- Hive 是Hadoop 的默认SQL 选项,每个版本都支持。而其他的要求特定的供应商和合适的用户;
- Hive 已经在减少和其他引擎的性能差距。大多数Hive 的替代者在2012年推出,分析师等待Hive 查询的完成等到要自杀。然而当Impala、Spark、Drill 等大步发展的时候,Hive只是一直跟着,慢慢改进。现在,虽然Hive 不是最快的选择,但是它比五年前要好得多;
- 虽然前沿的速度很酷,但是大多数机构都知道世界并没有尽头。即使一个年轻的市场经理需要等待10秒钟来查明上周二Duxbury 餐厅的鸡翅膀的销量是否超过了牛肉汉堡。
从DB-Engins中可以看出,相对于领先的商业数据仓库应用,用户对顶尖的SQL引擎更感兴趣。对于开源项目来说,最佳的健康度量是它的活跃开发者社区的大小。如下图所示,Hive和Presto有最大的贡献者基础。(Spark SQL的数据暂缺)

来源:Open Hub https://www.openhub.net
在2016年,Cloudera、Hortonworks、Kognitio 和Teradata 陷入了Tony Baer 总结的基准测试之战,令人震惊的是,供应商偏爱的SQL 引擎在每一个研究中都击败了其他选择,这带来一个问题:基准测试还有意义吗?
AtScale 一年两次的基准测试并不是毫无根据的。作为一个BI 初创公司,AtScale 销售衔接BI 前端和SQL 后端的软件。公司的软件是引擎中立的,它尝试尽可能多的兼容,其在BI 领域的广泛经验让这些测试有了实际的意义。
AtScale 最近的关键发现,包括了Hive、Impala、Spark SQL 和Presto:
- 4个引擎都成功运行了AtScale 的BI 基准查询;
- 取决于数据量、查询复杂度和并发用户数,每个引擎都有自己的性能优势:
Impala 和Spark SQL 在小数据量的查询上击败了其他人;
Impala 和Spark SQL 在大数据量的复杂join 上击败了其他人;
Impala 和Presto 在并发测试上表现的更好。
- 对比6个月之前的基准测试,所有的引擎都有了2-4倍的性能提升。
Alex Woodie 报告了测试结果,Andrew Oliver 对其进行分析。
让我们来深入了解这些项目。
Apache Hive
Apache Hive 是Hadoop 生态系统中的第一个SQL 框架。Facebook 的工程师在2007年介绍了Hive,并在2008年将代码捐献给Apache 软件基金会。2010年9月,Hive 毕业成为Apache 顶级项目。Hadoop 生态系统中的每个主要参与者都发布和支持Hive,包括Cloudera、MapR、Hortonworks 和IBM。Amazon Web Services 在Elastic MapReduce(EMR)中提供了Hive 的修改版作为云服务。
早期发布的Hive 使用MapReduce 运行查询。复杂查询需要多次传递数据,这会降低性能。所以Hive 不适合交互式分析。由Hortonworks 领导的Stinger 明显的提高了Hive 的性能,尤其是通过使用Apache Tez,一个精简MapReduce 代码的应用框架。Tez 和ORCfile,一种新的存储格式,对Hive 的查询产生了明显的提速。
Cloudera 实验室带领一个并行项目重新设计Hive 的后端,使其运行在Apache Spark 上。经过长期测试后,Cloudera 在2016年初发布了Hive-on-Spark 的正式版本。
在2016年,Hive 有100多人的贡献者。该团队在2月份发布了Hive 2.0,并在6月份发布了Hive 2.1。Hive 2.0 的改进包括了对Hive-on-Spark 的多个改进,以及性能、可用性、可支持性和稳定性增强。Hive 2.1 包括了Hive LLAP(”Live Long and Process“),它结合持久化的查询服务器和优化后的内存缓存,来实现高性能。该团队声称提高了25倍。
9月,Hivemall 项目进入了Apache 孵化器,正如我在我的机器学习年度总结的第二部分中指出的。Hivemall 最初由Treasure Data 开发并捐献给Apache 软件基金会,它是一个可扩展的机器学习库,通过一系列的Hive UDF 来实现,设计用于在Hive、Pig 和Spark SQL 上运行MapReduce。该团队计划在2017年第一季度发布了第一个版本。
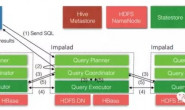
Apache Impala
2012年,Cloudera 推出了Impala,一个开源的MPP SQL 引擎,作为Hive 的高性能替代品。Impala 使用HDFS 和HBase,并利用了Hive 元数据。但是,它绕开了使用MapReduce 运行查询。
Cloudera 的首席战略官Mike Olson 在2013年底说到Hive 的架构是有根本缺陷的。在他看来,开发者只能用一种全新的方式来实现高性能SQL,例如Impala。2014年的1月、5月和9月,Cloudera 发布了一系列的基准测试。在这些测试中,Impala 展示了其在查询运行的逐步改进,并且显著优于基于Tez 的Hive、Spark SQL 和Presto。除了运行快速,Impala 在并发行、吞吐量和可扩展性上也表现优秀。2015年,Cloudera 将Impala 捐献给Apache 软件基金会,进入了Apache 孵化计划。Cloudera、MapR、Oracle 和Amazon Web Services 分发Impala,Cloudera、MapR 和Oracle 提供了商业构建和安装支持。
2016年,Impala 在Apache 孵化器中取得了稳步发展。该团队清理了代码,将其迁移到Apache 基础架构,并在10月份发布了第一个Apache 版本2.7.0。新版本包括了性能提升和可扩展性改进,以及一些其他小的增强。
9月,Cloudera 发布了一项研究结果,该研究比较了Impala 和Amazon Web Services 的Redshift 列存储数据库。报告读起来很有意思,虽然主题一贯的需要注意供应商的基准测试。
Spark SQL
Spark SQL 是Spark 用于结构化数据处理的组件。Apache Spark 团队 在2014年发布了Spark SQL,并吸收了一个叫Shark 的早期的Hive-on-Spark 项目。它迅速成为最广泛使用的Spark 模块。
Spark SQL 用户可以运行SQL 查询,从Hive 中读取数据,或者使用它来创建Spark Dataset和DataFrame(Dataset 是分布式的数据集合,DataFrame 是统一命名的Dataset 列)。Spark SQL 的接口向Spark 提供了数据结构和执行操作的信息,Spark 的Catalyst 优化器使用这些信息来构造一个高效的查询。
2015年,Spark 的机器学习开发人员引入了ML API,一个利用Spark DataFrame 代替低级别Spark RDD API 的包。这种方法被证明是有吸引力和富有成果的;2016年,随着2.0 的发布,Spark 团队将基于RDD 的API改为维护模式。DataFrame API现在是Spark 机器学习的主要接口。
此外,在2016年,该团队还在Spark 2.1.0的Alpha 版本中发布了结构化的流式处理。结构化的流式处理是构建在Spark SQL 上的一个流处理引擎。用户可以像对待静态源一样,用同样的方式查询流式数据源,并且可以在单个查询中组合流式和静态源。Spark SQL 持续运行查询,并且在流式数据到达的时候更新结果。结构化的流通过检查点和预写日志来提供一次性的容错保障。
Apache Drill
2012年,由Hadoop 分销商的领导者之一MapR 领导的一个团队,提出构建一个Google Dremel 的开源版本,一个交互式的分布式热点分析系统。他们将其命名为Apache Drill。Drill 在Apache 孵化器中被冷落了两年多,最终在2014年底毕业。该团队在2015年发布了1.0。
MapR 分发和支持Apache Drill。
2016年,超过50个人对Drill 做出了贡献。该团队在2016年发布了5个小版本,关键的增强功能包括:
- Web 认证
- 支持Apache Kudu 列数据库
- 支持HBase 1.x
- 动态UDF 支持
2015年,两位关键的Drill 贡献者离开了MapR,并启动了Dremio,该项目尚未发布。
Apache HAWQ
Pivotal 软件在2012年推出了一款商业许可的高性能SQL 引擎HAWQ,并在尝试市场营销时取得了小小的成功。改变战略后,Pivotal 在2015年6月将项目捐献给了Apache,并于2015年9月进入了Apache 孵化器程序。
15个月之后,HAWQ 仍然待在孵化器中。2016年12月,该团队发布了HAWQ 2.0.0.0,加入了一些错误修复。我猜它会在2017年毕业。
对HAWQ 喜爱的一个小点是它支持Apache MADlib,一个同样在孵化器中的SQL 机器学习项目。HAWQ 和MADlib 的组合,应该是对购买了Greenplum 并且想知道发生了什么的人们的一个很好的安慰。
Presto
Facebook工程师在2012年发起了Presto 项目,作为Hive 的一个快速交互的取代。在2013年推出时,成功的支持了超过1000个Facebook 用户和每天超过30000个PB级数据的查询。2013年Facebook开源了Presto。
Presto 支持多种数据源的ANSI SQL 查询,包括Hive、Cassandra、关系型数据库和专有文件系统(例如Amazon Web Service 的S3)。Presto 的查询可以联合多个数据源。用户可以通过C、Java、Node.js、PHP、Python、R和Ruby 来提交查询。
Airpal 是Airbnb 开发的一个基于web 的查询工具,让用户可以通过浏览器来提交查询到Presto。Qubole 位Presto 提供了管理服务。AWS 在EMR 上提供Presto 服务。
2015年6月,Teradata 宣布计划开发和支持该项目。根据宣布的三阶段计划,Teredata 提出将Presto 集成导Hadoop 生态系统中,能够在YARN 中进行操作,并且通过ODBC 和JDBC 增强连接性。Teredata 提供了自己的Presto 发行版,附带一份数据表。2016年6月,Teradata 宣布了Information Builders、Looker、Qlik、Tableau 和ZoomData 的鉴定结果,以及正在进行中的MicroStrategy 和Microsoft Power BI。
Presto 是一个非常活跃的项目,有一个巨大的和充满活力的贡献者社区。该团队发布的速度比Miki Sudo 吃热狗的速度还要快–我统计了下,2016年共发布了42个版本。Teradata 并没有打算总结有什么新的东西,我也不打算在42个发行说明里去筛选,所以就让我们说它更好吧。
其他Apache项目
这里还有5个其他的Apache生态系统的SQL混合项目。
Apache Calcite 是一个开源的数据库构建框架。它包括:
- SQL 解析器、验证器和JDBC 驱动
- 查询优化工具,包括关系代数API,基于规则的计划器和基于成本的查询优化器
Apache Hive 使用Calcite 进行基于成本的查询优化,而Apache Drill 和Apache Kylin 使用SQL 解析器。
Calcite 团队在2016年推出了5个版本包括bug 修复和用于Cassandra、Druid 和Elasticsearch 的新适配器。
Apache Kylin是一个具有SQL接口的OLAP引擎。由eBay 开发并捐献给Apache,Kylin 在2015年毕业成为顶级项目。
2016年成立的创业公司Kyligence 提供商业支持和一个叫做KAP 的数据仓库产品,虽然在Crunchbase 上没有列出它的资金情况,有消息来源称它有一个强大的背景,并且在上海有个大办公室。
Apache Phoenix 是一个运行在HBase 上的SQL 框架,绕过了MapReduce。Salesforce 开发了该软件并在2013年捐献给了Apache。2014年5月项目毕业成为顶级项目。Hortonworks 的Hortonworks 数据平台中包含该项目。自从领先的SQL 引擎都适配HBase 之后,我不清楚为什么我们还需要Phoenix。
Apache Tajo 是Gruter 在2011年推出的一个快速SQL 数据仓库框架,一个大数据基础设施公司,并在2013年捐献给Apache。2014年Tajo 毕业成为顶级项目。在作为Gruter 主要市场的韩国之外,该项目很少吸引到预期用户和贡献者的兴趣。除了Gartner 的Nick Heudecker 曾提过,该项目不在任何人的工作台上。
Apache Trafodion 是另一个SQL-on-HBase 项目,由HP 实验室构思,它告诉你几乎所有你需要知道的。2014年6月HP 发布Trafodion,一个月之后,Apache Phoenix 毕业投产。6个月之后,HP 的高管们认为相对于另一款SQL-on-HBase 引擎,它的商业潜力有限,所以他们将项目捐献给了Apache,项目于2015年5月进入孵化器。
如果孵化结束,Trafodion 承诺成为一个事务数据库。不幸的是,这个领域有大量的选择,而开发团队唯一的竞争优势似乎是“它是开源的,所以它很便宜”。