案例一
一、问题背景
最近生产环境出现多次Primary写入QPS太高,导致Seconary的同步无法跟上的问题(Secondary上的最新oplog时间戳比Primary上最旧oplog时间戳小),使得Secondary变成RECOVERING状态,这时需要人工介入处理,向Secondary发送resync命令,让Secondary重新全量同步一次。
二、同步过程
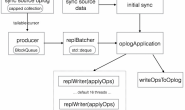
下图是MongoDB数据同步的流程:

Primary上的写入会记录oplog,存储到一个固定大小的capped collection里,Secondary主动从Primary上拉取oplog并重放应用到自身,以保持数据与Primary节点上一致。
initial sync
新节点加入(或者主动向Secondary发送resync)时,Secondary会先进行一次initial sync,即全量同步,遍历Primary上的所有DB的所有集合,将数据拷贝到自身节点,然后读取『全量同步开始到结束时间段内』的oplog并重放。全量同步不是本文讨论的重点,将不作过多的介绍。
tailing oplog
全量同步结束后,Secondary就开始从结束时间点建立tailable cursor,不断的从同步源拉取oplog并重放应用到自身,这个过程并不是由一个线程来完成的,mongodb为了提升同步效率,将拉取oplog以及重放oplog分到了不同的线程来执行。
- producer thread,这个线程不断的从同步源上拉取oplog,并加入到一个BlockQueue的队列里保存着,BlockQueue最大存储240MB的oplog数据,当超过这个阈值时,就必须等到oplog被replBatcher消费掉才能继续拉取。
- replBatcher thread,这个线程负责逐个从producer thread的队列里取出oplog,并放到自己维护的队列里,这个队列最多允许5000个元素,并且元素总大小不超过512MB,当队列满了时,就需要等待oplogApplication消费掉。
- oplogApplication会取出replBatch thread当前队列的所有元素,并将元素根据docId(如果存储引擎不支持文档锁,则根据集合名称)分散到不同的replWriter线程,replWriter线程将所有的oplog应用到自身;等待所有oplog都应用完毕,oplogApplication线程将所有的oplog顺序写入到local.oplog.rs集合。
producer的buffer和apply线程的统计信息都可以通过db.serverStatus().metrics.repl来查询到,在测试过程中,向Primary模拟约10000 qps的写入,观察Secondary上的同步,写入速率远小于Primary,大致只有3000左右的qps,同时观察到producer的buffer很快就达到饱和,可以判断出oplog重放的线程跟不上。
默认情况下,Secondary采用16个replWriter线程来重放oplog,可通过启动时设置replWriterThreadCount参数来定制线程数,当提升线程数到32时,同步的情况大大改观,主备写入的qps基本持平,主备上数据同步的延时控制在1s以内,进一步验证了上述结论。
三、改进思路
如果因Primary上的写入qps很高,经常出现Secondary同步无法追上的问题,可以考虑以下改进思路
- 配置更高的replWriterThreadCount,Secondary上加速oplog重放,代价是更高的内存开销
- 使用更大的oplog,可按照官方教程修改oplog的大小,阿里云MongoDB数据库增加了patch,能做到在线修改oplog的大小。
- 将writeOpsToOplog步骤分散到多个replWriter线程来并发执行,这个是官方目前在考虑的策略之一,参考Secondaries unable to keep up with primary under WiredTiger
附修改replWriterThreadCount参数的方法,具体应该调整到多少跟Primary上的写入负载如写入qps、平均文档大小等相关,并没有统一的值。
1.通过mongod命令行来指定
|
1 |
mongod --setParameter replWriterThreadCount=32 |
2.在配置文件中指定
|
1 2 |
setParameter: replWriterThreadCount: 32 |
案例二
前面介绍了因Primary上写入qps过大,导致Secondary节点的同步无法追上的问题,本文再分享一个case,因oplog的写入被放大,导致同步追不上的问题。
MongoDB用于同步的oplog具有一个重要的『幂等』特性,也就是说,一条oplog在备上重放多次,得到的结果跟重放一次结果是一样的,这个特性简化了同步的实现,Secondary不需要有专门的逻辑去保证一条oplog在备上『必须仅能重放』一次。
为了保证幂等性,记录oplog时,通常需要对写入的请求做一下转换,举个例子,某文档x字段当前值为100,用户向Primary发送一条{$inc: {x: 1}},记录oplog时会转化为一条{$set: {x: 101}的操作,才能保证幂等性。
一、幂等性的代价
简单元素的操作,$inc 转化为 $set并没有什么影响,执行开销上也差不多,但当遇到数组元素操作时,情况就不一样了。
当前文档内容:
|
1 2 |
mongo-9551:PRIMARY> db.coll.find() { "_id" : 1, "x" : [ 1, 2, 3 ] } |
在数组尾部push 2个元素,查看oplog发现$push操作被转换为了$set操作(设置数组指定位置的元素为某个值)。
|
1 2 3 4 5 6 7 8 |
mongo-9551:PRIMARY> db.coll.update({_id: 1}, {$push: {x: { $each: [4, 5] }}}) WriteResult({ "nMatched" : 1, "nUpserted" : 0, "nModified" : 1 }) mongo-9551:PRIMARY> db.coll.find() { "_id" : 1, "x" : [ 1, 2, 3, 4, 5 ] } mongo-9551:PRIMARY> use local switched to db local mongo-9551:PRIMARY> db.oplog.rs.find().sort({$natural: -1}).limit(1) { "ts" : Timestamp(1464081601, 1), "h" : NumberLong("7793405363406192063"), "v" : 2, "op" : "u", "ns" : "test.coll", "o2" : { "_id" : 1 }, "o" : { "$set" : { "x.3" : 4, "x.4" : 5 } } } |
$push转换为带具体位置的$set开销上也差不多,但接下来再看看往数组的头部添加2个元素。
|
1 2 3 4 5 6 7 8 |
mongo-9551:PRIMARY> db.coll.update({_id: 1}, {$push: {x: { $each: [6, 7], $position: 0 }}}) WriteResult({ "nMatched" : 1, "nUpserted" : 0, "nModified" : 1 }) mongo-9551:PRIMARY> db.coll.find() { "_id" : 1, "x" : [ 6, 7, 1, 2, 3, 4, 5 ] } mongo-9551:PRIMARY> use local switched to db local mongo-9551:PRIMARY> db.oplog.rs.find().sort({$natural: -1}).limit(1) { "ts" : Timestamp(1464082056, 1), "h" : NumberLong("6563273714951530720"), "v" : 2, "op" : "u", "ns" : "test.coll", "o2" : { "_id" : 1 }, "o" : { "$set" : { "x" : [ 6, 7, 1, 2, 3, 4, 5 ] } } } |
可以发现,当向数组的头部添加元素时,oplog里的$set操作不再是设置数组某个位置的值(因为基本所有的元素位置都调整了),而是$set数组最终的结果,即整个数组的内容都要写入oplog。当push操作指定了$slice或者$sort参数时,oplog的记录方式也是一样的,会将整个数组的内容作为$set的参数。
$pull, $addToSet等更新操作符也是类似,更新数组后,oplog里会转换成$set数组的最终内容,才能保证幂等性。
二、案例分析
当数组非常大时,对数组的一个小更新,可能就需要把整个数组的内容记录到oplog里,我们遇到一个实际的生产环境案例,用户的文档内包含一个很大的数组字段,1000个元素总大小在64KB左右,这个数组里的元素按时间反序存储,新插入的元素会放到数组的最前面($position: 0),然后保留数组的前1000个元素($slice: 1000)。
上述场景导致,Primary上的每次往数组里插入一个新元素(请求大概几百字节),oplog里就要记录整个数组的内容,Secondary同步时会拉取oplog并重放,『Primary到Secondary同步oplog』的流量是『客户端到Primary网络流量』的上百倍,导致主备间网卡流量跑满,而且由于oplog的量太大,旧的内容很快被删除掉,最终导致Secondary追不上,转换为RECOVERING状态。
MongoDB对json的操作支持很强大,尤其是对数组的支持,但在文档里使用数组时,一定得注意上述问题,避免数组的更新导致同步开销被无限放大的问题。使用数组时,尽量注意
- 数组的元素个数不要太多,总的大小也不要太大。
- 尽量避免对数组进行更新操作。
- 如果一定要更新,尽量只在尾部插入元素,复杂的逻辑可以考虑在业务层面上来支持。
比如上述场景,有如下的改进思路
- 将数组的内容放到单独的集合存储,将数组的操作转化为对集合的操作(capped collection能很好的支持$slice的功能)。
- 如果一定要用数组,插入数组元素时,直接放到尾部,让记录就是按时间戳升序存储,在使用时反向遍历({$natural: -1})取最新的元素。保持最近1000条的功能,则可在业务逻辑里实现掉,比如增加后台任务来检测,当数组元素超过某个阈值如2000时,就将数组截断到1000条。
三、改进思路
为了尽量避免出现Secondary追不上的场景,需要注意以下几点
- 保证Primary节点有充足的服务能力,如果用户的请求就能把Primary的资源跑得很满,那么势必会影响到主备同步。
- 合理配置oplog的大小,可以结合写入的情况,预估下oplog的大小,比如oplog能存储一天的写入量,这样即使备同步慢、故障、或者临时下线维护等,只要不超过1天,恢复后还是有希望继续同步的。
- 尽量避免复杂的数组更新操作,尽量避免慢更新(比如更新的查询条件需要遍历整个集合)
<原文>
https://yq.aliyun.com/articles/57755?spm=5176.8091938.0.0.Opu19P
https://yq.aliyun.com/articles/52404?spm=5176.100239.blogcont57755.12.xZgM4j