一、RabbitMQ历史
RabbitMQ消息系统是一个由erlang开发的AMQP(Advanced Message Queue )的开源实现。在同步消息通讯的世界里有很多公开标准(如COBAR的IIOP,或者是SOAP等),但是在异步消息处理中却不是这样,只有大企业有一些商业实现(如微软的MSMQ ,IBM的Websphere MQ等),因此,在2006年的6月,Cisco 、Redhat、iMatix 等联合制定了AMQP的公开标准。
RabbitMQ是由RabbitMQ Technologies Ltd开发并且提供商业支持的。该公司在2010年4月被SpringSource(VMWare的一个部门)收购。在2013年5月被并入Pivotal。
RabbitMQ是一个消息代理:它接受并转发消息。你可以把它当成一个邮局:当你想邮寄信件的时候,你会把信件放在投递箱中,并确信邮递员最终会将信件送到收件人的手里。在这个例子中,RabbitMQ就相当与投递箱、邮局和邮递员。
二、RabbitMQ能为你做些什么?
言归正传,RabbitMQ,或者说AMQP解决了什么问题,或者说它的应用场景是什么?
消息系统允许软件应用相互连接和扩展,这些应用可以相互链接起来组成一个更大的应用,或者将用户设备和数据进行连接。消息系统通过将消息的发送和接收分离来实现应用程序的异步和解偶。或许你正在考虑进行数据投递,非阻塞操作或推送通知。或许你想要实现发布/订阅,异步处理,或者工作队列。所有这些都属于消息系统的模式。RabbitMQ是一个消息代理,一个消息系统的媒介。它可以为你的应用提供一个通用的消息发送和接收平台,并且保证消息再传输过程中的安全。
对于一个大型的软件系统来说,它会有很多的组件或者说模块或者说子系统。那么这些模块的如何通信?这和传统的IPC有很大的区别。传统的IPC很多都是在单一系统上的,模块耦合性很大,不适合扩展(Scalability);如果使用socket那么不同的模块的确可以部署到不同的机器上,但是还是有很多问题需要解决。比如:
1)信息的发送者和接收者如何维持这个连接,如果一方的连接中断,这期间的数据如何方式丢失?
2)如何降低发送者和接收者的耦合度?
3)如何让Priority高的接收者先接到数据?
4)如何做到load balance?有效均衡接收者的负载?
5)如何有效的将数据发送到相关的接收者?也就是说将接收者subscribe不同的数据,如何做有效的filter。
6)如何做到可扩展,甚至将这个通信模块发到cluster上?
7)如何保证接收者接收到了完整,正确的数据?
AMDQ协议解决了以上的问题,而RabbitMQ实现了AMQP。
三、Rabbitmq工作模式
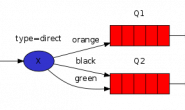
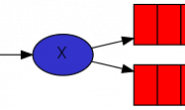
AMQP协议中的核心思想就是生产者和消费者隔离,生产者从不直接将消息发送给队列。生产者通常不知道是否一个消息会被发送到队列中,只是将消息发送到一个Exchange(交换机)。先由Exchange来接收,然后Exchange按照特定的策略转发到Queue进行存储。同理,消费者也是如此。Exchange 就类似于一个交换机,转发各个消息分发到相应的队列中。
")
如上图:
RabbitMQ Server
是一种传输服务,它的角色就是维护一条从Producer(生产者)到Consumer(消费者)的路线,保证数据能够按照指定的方式进行传输。但是这个保证也不是100%的保证,但是对于普通的应用来说这已经足够了。当然对于商业系统来说,可以再做一层数据一致性的防护,就可以彻底保证系统的一致性了。
Client A & B
也叫Producer(生产者),就是数据的发送方。一个Message(消息)有两个部分:payload(有效载荷)和label(标签)。payload顾名思义就是传输的数据。label是exchange的名字或者说是一个tag,它描述了payload,而且RabbitMQ也是通过这个label来决定把这个Message发给哪个Consumer(消费者)。AMQP仅仅描述了label,而RabbitMQ决定了如何使用这个label的规则。
Client 1 & 2 & 3
也叫Consumer(消费者),就是数据的接收方。把queue(队列)比作是一个有名字的邮箱,当有Message到达某个邮箱后,RabbitMQ把它发送给它的某个订阅者即Consumer。当然可能会把同一个Message发送给很多的Consumer。在这个Message中,只有payload,label已经被删掉了。对于Consumer来说,它是不知道谁发送的这个信息的。就是协议本身不支持。但是如果Producer发送的payload包含了Producer的信息就另当别论了。
对于一个数据从Producer到Consumer的正确传递,还有三个概念需要明确:exchanges, queues and bindings。
Exchanges – 是生产者发布消息的通道。
Queue – 是消费者接受消息的通道。
Bindings – 是将消息从交换路由绑定到特定队列中的。
还有几个概念是上述图中没有标明的,那就是Connection(连接),Channel(通道,频道)。
Connection – 就是一个TCP的连接,Producer和Consumer都是通过TCP连接到RabbitMQ Server的。以后我们可以看到,程序的起始处就是建立这个TCP连接。
Channels – 虚拟连接,它建立在上述的TCP连接中。数据流动都是在Channel中进行的。也就是说,一般情况是程序起始建立TCP连接,第二步就是建立这个Channel。
那么,为什么使用Channel,而不是直接使用TCP连接?
对于OS来说,建立和关闭TCP连接是有代价的,频繁的建立关闭TCP连接对于系统的性能有很大的影响,而且TCP的连接数也有限制,这也限制了系统处理高并发的能力。但是,在TCP连接中建立Channel是没有上述代价的。对于Producer或者Consumer来说,可以并发的使用多个Channel进行Publish或者Receive。有实验表明,1s的数据可以Publish 10K的数据包。当然对于不同的硬件环境,不同的数据包大小这个数据肯定不一样,但是我只想说明,对于普通的Consumer或者Producer来说,这已经足够了。如果不够用,你考虑的应该是如何细化split你的设计。
四、Rabbitmq技术亮点
1)可靠性
RabbitMQ提供了多种技术可以让你在性能和可靠性之间进行权衡。这些技术包括持久性、投递确认、发布者证实和高可用性。
2)灵活的路由
消息在到达队列前是通过交换机进行路由的。RabbitMQ为典型的路由逻辑提供了多种内置交换机类型。如果你有更复杂的路由需求,可以将这些交换机组合起来使用,甚至你可以写自己的交换机类型,并且当做RabbitMQ的插件来使用。
3)集群
在相同局域网中的多个RabbitMQ服务器可以被聚合在一起,作为一个独立的逻辑代理来使用。
4)联合
对于服务器来说,它比集群需要更多的松散和非可靠链接。为此RabbitMQ提供了联合模型。
5)高可用的队列
在同一个集群中,队列可以被镜像到多个机器中,以确保当其中某些硬件出现事故后,你的消息仍然是安全的。
6)多协议
RabbitMQ 支持多种消息协议中的消息传递。
7)广泛的客户端
只要是你能想到的语言几乎都有与其相适配的RabbitMQ客户端。
8)可视化管理工具
RabbitMQ附带了一个易于使用的可视化管理工具,它可以帮助你监控消息代理的每一个环节。
9)追踪
如果你的消息系统有异常行为,RabbitMQ还提供了追踪的支持,让你能够发现问题所在。
10)插件系统
RabbitMQ附带了各种各样的插件来对自己进行扩展。甚至你也可以写自己的插件来使用。
11)还有什么呢…
商业支持
可以提供商业支持,包括培训和咨询。
大型社区
围绕着RabbitMQ有一个大型的社区,在那儿产生了各种各样的客户端、插件、指南等等。
五、六种工作模式
官网介绍:https://www.rabbitmq.com/getstarted.html
这里简单介绍下六种工作模式的主要特点:
简单模式:一个生产者,一个消费者
work模式:一个生产者,多个消费者,每个消费者获取到的消息唯一。
订阅模式:一个生产者发送的消息会被多个消费者获取。
路由模式:发送消息到交换机并且要指定路由key,消费者将队列绑定到交换机时需要指定路由key。
topic模式:将路由键和某模式进行匹配,此时队列需要绑定在一个模式上,“#”匹配一个词或多个词,“*”只匹配一个词。
六、RabbitMQ FAQ
RabbitMQ是使用Erlang开发的一个消息队列,可以构建成集群,也可以单独使用。
根据测试,RabbitMQ在不使用ACK机制的,Msg大小为1K的情况下,QPS可达6W+。在双方ACK机制,Msg大小为1K的情况下,QPS瞬间降到了1W+。从某种意义上RabbitMQ还真是慢,但是我们需要思考下。
- 我们真的每个消息都能到1K吗?
- 我们真的需要双方都对消息ACK的系统吗?
好了,如果两个回答都是YES,那么RabbitMQ就是慢的。如果是No,那么RabbitMQ还是一个非常快的队列。
RabbitMQ慢有几个原因?
- RabbitMQ做为一个Broker,不单单做到了简单的数据转发功能,还保证了单个队列上的数据有序,即便是有多个消费者和多个生产者。
- RabbitMQ的策略是实时转发,而不像Kafka那样等待刷盘之后才让消费者来消费。
- 如果消费者和生产者不对等,会产生大量的磁盘IO操作,进行消息换出。
RabbitMQ为什么不好用?
- AMQP协议本身比较复杂,参数比较多。
- Erlang写的,很多人不熟悉,并且Mnesia出现问题好多人解决不了。
RabbitMQ该怎么用?
- RabbitMQ的消息应当尽可能的小,并且只用来处理实时且要高可靠性的消息。
- 消费者和生产者的能力尽量对等,否则消息堆积会严重影响RabbitMQ的性能。
- 集群部署,使用热备,保证消息的可靠性。