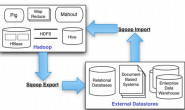
Hive的介绍
Hive是一个强大的工具。它使用了HDFS,元数据存储(默认情况下是一个 Apache Derby 数据库)、shell命令、驱动器、编译器和执行引擎。它还支持Java数据库连接性 (JDBC) 连接。 由于其类似SQL的能力和类似数据库的功能,Hive能够为非编程人员打开大数据Hadoop生态系统。它还提供了外部BI软件,例如,通过 JDBC驱动器和Web客户端和Cognos连接。
您可以依靠现有的数据库开发人员,不用费时费力地寻找Java MapReduce编程人员。这样做的好处在于:您可以让一个数据库开发人员编写10-15行SQL代码,然后将它优化和翻译为MapReduce代码,而不是强迫一个非编程人员或者编程人员写200行代码,甚至更多的复杂MapReduce代码。
Hive常被描述为构建于Hadoop之上的数据仓库基础架构。事实是,Hive与数据仓库没有什么关系。如果您想构建一个真实的数据仓库,可以借助一些工具,比如 IBM Netezza。但是如果您想使用Hadoop构建一个数据库,但又没有掌握Java或者MapReduce方面的知识,那么Hive会是一个非常不错的选择(如果您了解 SQL)。Hive允许您使用Hadoop和HBase的HiveQL编写类似SQL的查询,还允许您在HDFS之上构建星型模型。
Hive的限制
在使用Hive时可能会有一些挑战。首先,它与SQL-92不兼容。某些标准的SQL函数,例如NOT IN、NOT LIKE和NOT EQUAL并不存在,或者需要某种工作区。类似地,部分数学函数有严格限制,或者不存在。时间戳或者date是最近添加的值,与SQL日期兼容性相比,更具有Java日期兼容性。一些简单功能,例如数据差别,不能正常工作。
此外,Hive不是为了获得低延时的、实时或者近乎实时的查询而开发的。SQL查询被转化成MapReduce,这意味着与传统RDBMS 相比,对于某种查询,性能可能较低。
另一个限制是,元数据存储默认情况下是一个Derby数据库,并不是为企业或者生产而准备。部分Hadoop用户转而使用外部数据库作为元数据存储(如MySQL),但是这些外部元数据存储也有其自身的难题和配置问题。这也意味着需要有人在Hadoop外部维护和管理RDBMS系统。
Hive安装配置
安装Hive需要Java支持,另外,需要在安装有Hadoop的机器上运行。如果你安装过Hadoop集群,那么应该知道Hadoop也需要Java环境,所以Hive又需要安装在Hadoop机器上,结论就是Java其实是应该已经安装过的,也可以看一下Java安装流程。
安装Java
|
1 |
$ yum install java java-devel -y |
查看java版本,确保此命令没有问题
|
1 2 3 4 |
$ java -version openjdk version "1.8.0_131" OpenJDK Runtime Environment (build 1.8.0_131-b12) OpenJDK 64-Bit Server VM (build 25.131-b12, mixed mode) |
另外openjdk安装后,不会默许设置JAVA_HOME环境变量,要查看安装后的目录,可以用命令。
|
1 2 3 4 |
$ update-alternatives --config java Selection Command ----------------------------------------------- *+ 1 java-1.8.0-openjdk.x86_64 (/usr/lib/jvm/java-1.8.0-openjdk-1.8.0.131-3.b12.el7_3.x86_64/jre/bin/java) |
默认jre目录为:/usr/lib/jvm/java-1.8.0-openjdk-1.8.0.131-3.b12.el7_3.x86_64
设置环境变量,可用编辑/etc/profile.d/java.sh
|
1 2 3 4 5 |
#!/bin/bash # export JAVA_HOME=/usr/lib/jvm/java-1.8.0-openjdk-1.8.0.131-3.b12.el7_3.x86_64 export CLASSPATH=.:$JAVA_HOME/lib/rt.jar:$JAVA_HOME/jre/lib/dt.jar:$JAVA_HOME/lib/tools.jar export PATH=$PATH:$JAVA_HOME/bin |
完成这项操作之后,需要重新登录,或source一下profile文件,以便环境变量生效,当然也可以手工运行一下,以即时生效。
解压安装Hive
|
1 2 3 |
$ wget http://mirrors.hust.edu.cn/apache/hive/hive-2.1.1/apache-hive-2.1.1-bin.tar.gz $ tar xvf apache-hive-2.1.1-bin.tar.gz -C /usr/local/ $ ln -sv /usr/local/apache-hive-2.1.1-bin/ /usr/local/hive |
设置Hive环境变量
|
1 2 3 4 5 |
$ cat /etc/profile.d/hive.sh #!/bin/bash # export HIVE_HOME=/usr/local/hive export PATH=$PATH:$HIVE_HOME/bin |
|
1 |
$ source /etc/profile |
配置Hive
Hive提供了配置文件模板,所以需要复制一份出来。
|
1 2 3 4 5 |
$ cd /usr/local/hive/conf $ cp hive-env.sh.template hive-env.sh $ cp hive-default.xml.template hive-site.xml $ cp hive-log4j2.properties.template hive-log4j2.properties $ cp hive-exec-log4j2.properties.template hive-exec-log4j2.properties |
修改hive-env.sh
因为Hive使用了Hadoop,需要在hive-env.sh文件中指定Hadoop安装路径:
|
1 2 3 4 |
export JAVA_HOME=/usr/lib/jvm/java-1.8.0-openjdk-1.8.0.131-3.b12.el7_3.x86_64 #Java_home路径; export HADOOP_HOME=/usr/local/hadoop #Hadoop安装路径; export HIVE_HOME=/usr/local/hive #Hive安装路径; export HIVE_CONF_DIR=/usr/local/hive/conf #Hive配置文件路径; |
创建HDFS目录
在Hive中创建表之前需要创建以下HDFS目录并给它们赋相应的权限。
|
1 2 3 4 5 6 7 |
$ su - hadoop $ hdfs dfs -mkdir -p /user/hive/warehouse $ hdfs dfs -mkdir -p /user/hive/tmp $ hdfs dfs -mkdir -p /user/hive/log $ hdfs dfs -chmod a+w /user/hive/warehouse $ hdfs dfs -chmod a+w /user/hive/tmp $ hdfs dfs -chmod a+w /user/hive/log |
修改hive-site.xml
将hive-site.xml文件中以下几个配置项的值设置成上一步中创建的几个路径。
|
1 2 3 4 5 6 7 8 |
<property> <name>hive.exec.scratchdir</name> <value>/user/hive/tmp</value> <description> HDFS root scratch dir for Hive jobs which gets created with write all (733) permission. For each connecting user, an HDFS scratch dir: ${hive.exec.scratchdir}/<username> is created, with ${hive.scratch.dir.permission}. </description> </property> |
Hive Metastore
默认情况下, Hive的元数据保存在内嵌的Derby数据库里,但一般情况下生产环境会使用MySQL来存放Hive元数据,Derby会在当前目录生成元数据,而不是所有会话共享,所以一定要使用MySQL。
创建数据库和用户
假定你已经安装好MySQL,下面创建一个 hive数据库用来存储Hive元数据,且数据库访问的用户名和密码都为hive。
|
1 2 3 4 |
mysql> create database hive; mysql> grant all on hive.* to'hive'@'%' identified by 'hive'; mysql> grant all on hive.* to'hive'@'localhost' identified by 'hive'; mysql> flush privileges; |
修改hive-site.xml
需要在hive-site.xml文件中配置MySQL数据库连接信息。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 |
<configuration> <!--以下是MySQL连接信息--> <property> <name>javax.jdo.option.ConnectionURL</name> <value>jdbc:mysql://127.0.0.1:3306/hive?createDatabaseIfNotExist=true</value> </property> <property> <name>javax.jdo.option.ConnectionDriverName</name> <value>com.mysql.jdbc.Driver</value> </property> <property> <name>javax.jdo.option.ConnectionUserName</name> <value>hive</value> </property> <property> <name>javax.jdo.option.ConnectionPassword</name> <value>hive</value> </property> </configuration> |
运行Hive
Hive启动有三种方式:
1)Hive命令行模式,直接输入hive的执行程序,或者输入hive –service cli 进入命令行模式。用于Linux平台命令行查询,查询语句基本跟MySQL查询语句类似。
2)Hive Web界面的启动方式:hive –service hwi ,用于通过浏览器来访问Hive,感觉没多大用途。
3)Hive远程服务 (默认端口号10000) 启动方式:nohup hive –service hiveserver2 10000 & 。用java等程序实现通过jdbc等驱动的访问hive就用这种起动方式了,这个是程序员最需要的方式了。
在命令行运行Hive命令时必须保证以下两点:
HDFS已经启动,可以使用start-dfs.sh脚本来启动HDFS。
MySQL Java连接器添加到$HIVE_HOME/lib目录下,我安装时使用的是mysql-connector-java.jar。
|
1 2 3 4 5 6 7 8 9 10 11 12 |
$ yum install mysql-connector-java $ rpm -ql mysql-connector-java /usr/share/doc/mysql-connector-java-5.1.25 /usr/share/doc/mysql-connector-java-5.1.25/CHANGES /usr/share/doc/mysql-connector-java-5.1.25/COPYING /usr/share/doc/mysql-connector-java-5.1.25/docs /usr/share/doc/mysql-connector-java-5.1.25/docs/README.txt /usr/share/doc/mysql-connector-java-5.1.25/docs/connector-j.html /usr/share/doc/mysql-connector-java-5.1.25/docs/connector-j.pdf /usr/share/java/mysql-connector-java.jar /usr/share/maven-fragments/mysql-connector-java /usr/share/maven-poms/JPP-mysql-connector-java.pom |
把mysql-connector-java.jar复制到$HIVE_HOME/lib。
|
1 |
$ cp -fr /usr/share/java/mysql-connector-java.jar /usr/local/hive/lib/ |
从Hive 2.1版本开始,我们需要先运行schematool命令来执行初始化操作。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 |
$ schematool -dbType mysql -initSchema SLF4J: Class path contains multiple SLF4J bindings. SLF4J: Found binding in [jar:file:/usr/local/apache-hive-2.1.1-bin/lib/log4j-slf4j-impl-2.4.1.jar!/org/slf4j/impl/StaticLoggerBinder.class] SLF4J: Found binding in [jar:file:/usr/local/hadoop-2.8.0/share/hadoop/common/lib/slf4j-log4j12-1.7.10.jar!/org/slf4j/impl/StaticLoggerBinder.class] SLF4J: See http://www.slf4j.org/codes.html#multiple_bindings for an explanation. SLF4J: Actual binding is of type [org.apache.logging.slf4j.Log4jLoggerFactory] Metastore connection URL: jdbc:mysql://127.0.0.1:3306/hive?createDatabaseIfNotExist=true Metastore Connection Driver : com.mysql.jdbc.Driver Metastore connection User: hive Starting metastore schema initialization to 2.1.0 Initialization script hive-schema-2.1.0.mysql.sql Initialization script completed schemaTool completed |
执行完成后可以去看一下MySQL的Hive库中已经生成了很多表。
|
1 2 3 4 5 6 7 8 9 10 |
mysql> show tables from hive; +---------------------------+ | Tables_in_hive | +---------------------------+ | AUX_TABLE | | BUCKETING_COLS | | CDS | | COLUMNS_V2 | | COMPACTION_QUEUE | .............. |
使用Hive CLI(Hive command line interface), 可以在终端输入以下命令:
|
1 2 3 4 5 6 7 8 9 10 |
$ hive SLF4J: Class path contains multiple SLF4J bindings. SLF4J: Found binding in [jar:file:/usr/local/apache-hive-2.1.1-bin/lib/log4j-slf4j-impl-2.4.1.jar!/org/slf4j/impl/StaticLoggerBinder.class] SLF4J: Found binding in [jar:file:/usr/local/hadoop-2.8.0/share/hadoop/common/lib/slf4j-log4j12-1.7.10.jar!/org/slf4j/impl/StaticLoggerBinder.class] SLF4J: See http://www.slf4j.org/codes.html#multiple_bindings for an explanation. SLF4J: Actual binding is of type [org.apache.logging.slf4j.Log4jLoggerFactory] Logging initialized using configuration in file:/usr/local/apache-hive-2.1.1-bin/conf/hive-log4j2.properties Async: true Hive-on-MR is deprecated in Hive 2 and may not be available in the future versions. Consider using a different execution engine (i.e. spark, tez) or using Hive 1.X releases. hive> |
然后你就可以像使用SQL一样来操作HDFS了,如下:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 |
hive> create database db_test; OK Time taken: 0.124 seconds hive> show databases; OK db_test default Time taken: 0.901 seconds, Fetched: 1 row(s) hive> use db_test; OK Time taken: 0.015 seconds hive> show tables; OK Time taken: 0.02 seconds |
真正使用Hive,还需要把数据从本地或HDFS中加载到Hive对应的表中,Hive支持多种表类型,如内部表、外部表、分区表、桶表等。每个表类型解决的问题不同。后面就会对这几种表类型进行测试。
使用Hive构建数据库:https://www.ibm.com/developerworks/cn/data/library/bd-hivelibrary/index.html